Introduction
Textual content-to-image synthesis and image-text contrastive studying are two of probably the most progressive multimodal studying purposes not too long ago gaining recognition. With their progressive purposes for inventive picture creation and manipulation, these fashions have revolutionized the analysis group and drawn important public curiosity.
With a view to do additional analysis, DeepMind launched Imagen. This text-to-image diffusion mannequin presents unprecedented photorealism and a profound understanding of language in text-to-image synthesis by fusing the energy of transformer language fashions (LMs) with high-fidelity diffusion fashions.
This text describes the coaching and evaluation of Google’s latest Imagen mannequin, Imagen 3. Imagen 3 might be configured to output photos at 1024 × 1024 decision by default, with the choice to use 2×, 4×, or 8× upsampling afterward. We define our analyses and assessments compared to different cutting-edge T2I fashions.
We found that Imagen 3 is the most effective mannequin. It excels at photorealism and following intricate and prolonged person directions.

Overview
- Revolutionary Textual content-to-Picture Mannequin: Google’s Imagen 3, a text-to-image diffusion mannequin, delivers unmatched photorealism and precision in deciphering detailed person prompts.
- Analysis and Comparability: Imagen 3 excels in prompt-image alignment and visible enchantment, surpassing fashions like DALL·E 3 and Secure Diffusion in each automated and human evaluations.
- Dataset and Security Measures: The coaching dataset undergoes stringent filtering to take away low-quality or dangerous content material, guaranteeing safer, extra correct outputs.
- Architectural Brilliance: Utilizing a frozen T5-XXL encoder and multi-step upsampling, Imagen 3 generates extremely detailed photos as much as 1024 × 1024 decision.
- Actual-World Integration: Imagen 3 is accessible through Google Cloud’s Vertex AI, making it straightforward to combine into manufacturing environments for inventive picture technology.
- Superior Options and Velocity: With the introduction of Imagen 3 Quick, customers can profit from a 40% discount in latency with out compromising picture high quality.
Dataset: Guaranteeing High quality and Security in Coaching
The Imagen mannequin is educated utilizing a big dataset that features textual content, photos, and associated annotations. DeepMind used a number of filtration phases to ensure high quality and security necessities. First, any photos deemed harmful, violent, or poor high quality are eliminated. Subsequent, DeepMind eliminated photos created by AI to cease the mannequin from choosing up biases or artifacts ceaselessly current in these sorts of photos. DeepMind additionally employed down-weighting comparable photos and deduplication procedures to cut back the potential of outputs overfitting sure coaching knowledge factors.
Each picture within the dataset has an artificial caption and an authentic caption derived from alt textual content, human descriptions, and many others. Gemini fashions produce artificial captions with totally different cues. To maximise the language variety and high quality of those artificial captions, DeepMind used a number of Gemini fashions and directions. DeepMind used varied filters to remove doubtlessly dangerous captions and personally identifiable info.
Structure of Imagen
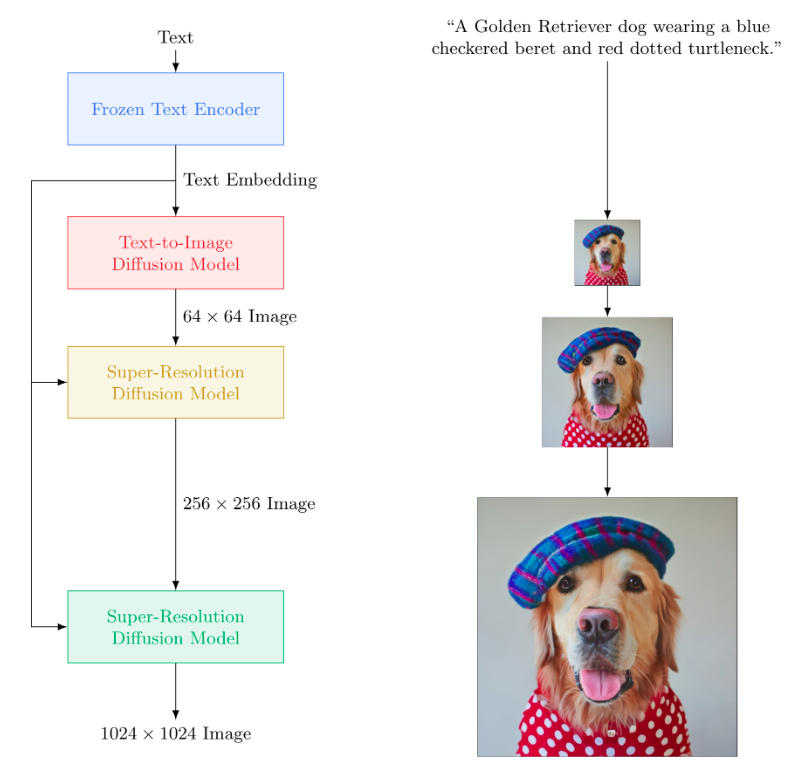
Imagen makes use of a big frozen T5-XXL encoder to encode the enter textual content into embeddings. A conditional diffusion mannequin maps the textual content embedding right into a 64×64 picture. Imagen additional makes use of text-conditional super-resolution diffusion fashions to upsample the picture 64×64→256×256 and 256×256→1024×1024.
Analysis of Imagen Fashions
DeepMind evaluates the Imagen 3 mannequin, which is the very best quality configuration, towards the Imagen 2 and the exterior fashions DALL·E 3, Midjourney v6, Secure Diffusion 3 Massive, and Secure Diffusion XL 1.0. DeepMind discovered that Imagen 3 units a brand new cutting-edge in text-to-image technology by means of rigorous evaluations by people and machines. Qualitative Outcomes and Inference on Analysis comprise qualitative outcomes and a dialogue of the general findings and limitations. Product integrations with Imagen 3 might lead to efficiency that’s totally different from the configuration that was examined.
Additionally learn: Methods to Use DALL-E 3 API for Picture Technology?
Human Analysis: How Raters Judged Imagen 3’s Output High quality?
The text-to-image technology mannequin is evaluated on 5 high quality points: total desire, prompt-image alignment, visible enchantment, detailed prompt-image alignment, and numerical reasoning. These points are independently assessed to keep away from conflation in raters’ judgments. Aspect-by-side comparisons are used for quantitative judgment, whereas numerical reasoning might be evaluated immediately by counting what number of objects of a given sort are depicted in a picture.
The whole Elo scoreboard is generated by means of an exhaustive comparability of each pair of fashions. Every examine consists of 2500 rankings uniformly distributed among the many prompts within the immediate set. The fashions are anonymized within the rater interface, and the perimeters are randomly shuffled for each score. Information assortment is carried out utilizing Google DeepMind’s greatest practices on knowledge enrichment, guaranteeing all knowledge enrichment employees are paid not less than a neighborhood residing wage. The examine collected 366,569 rankings in 5943 submissions from 3225 totally different raters. Every rater participated in at most 10% of the research and offered roughly 2% of the rankings to keep away from biased outcomes to a specific set of raters’ judgments. Raters from 71 totally different nationalities participated within the research.
Total Consumer Desire: Imagen 3 Takes the Lead in Artistic Picture Technology
The general desire of customers relating to the generated picture given a immediate is an open query, with raters deciding which high quality points are most vital. Two photos had been offered to raters, and if each had been equally interesting, “I’m detached.”
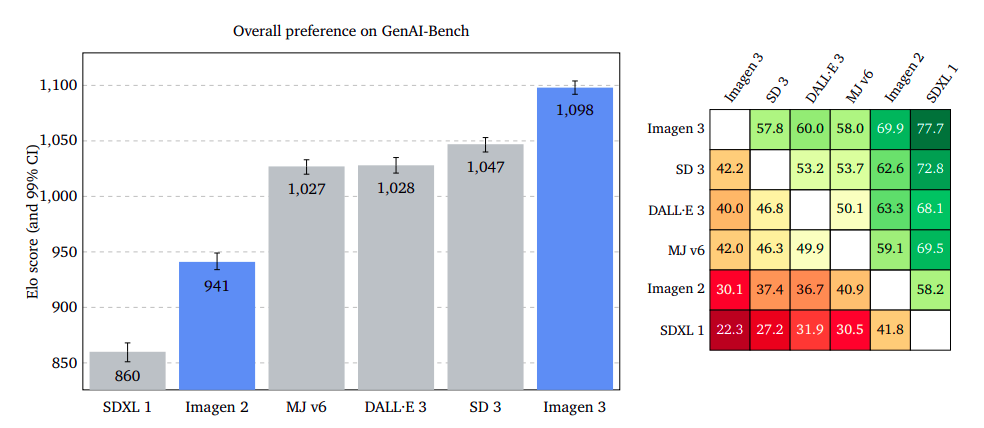
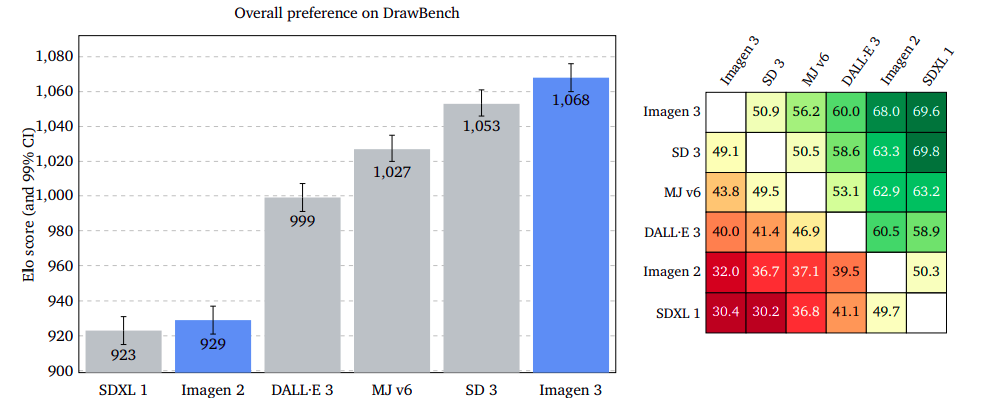
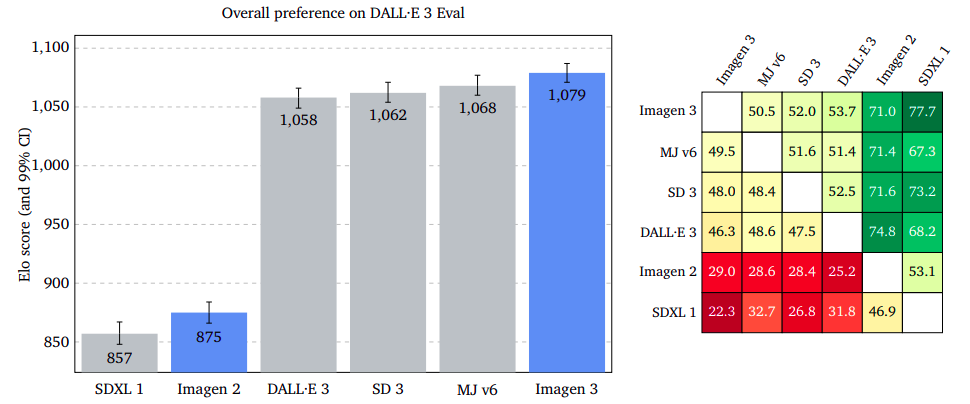
Outcomes confirmed that Imagen 3 was considerably extra most well-liked on GenAI-Bench, DrawBench, and DALL·E 3 Eval. Imagen 3 led with a smaller margin on DrawBench than Secure Diffusion 3, and it had a slight edge on DALL·E 3 Eval.
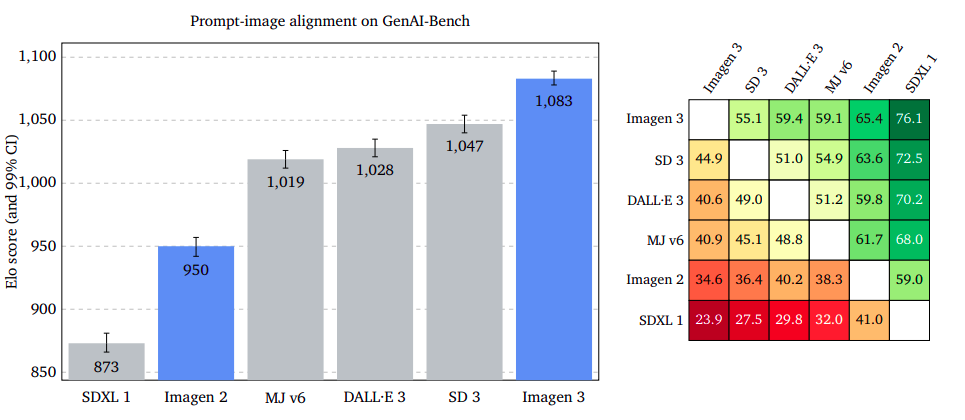
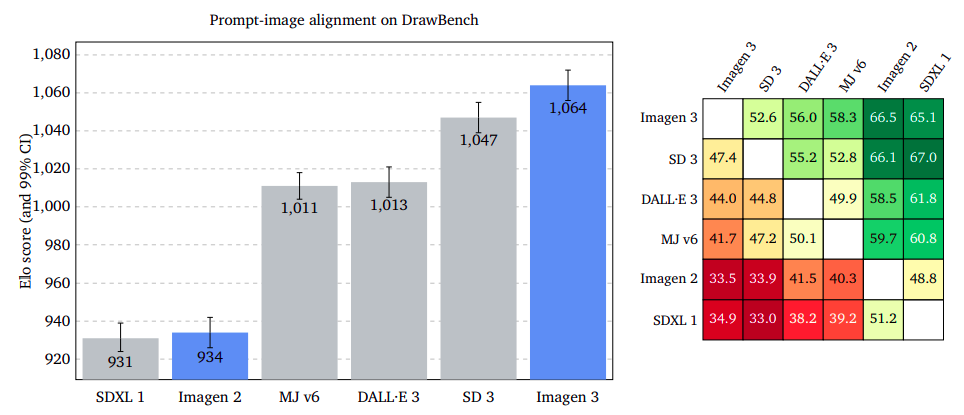
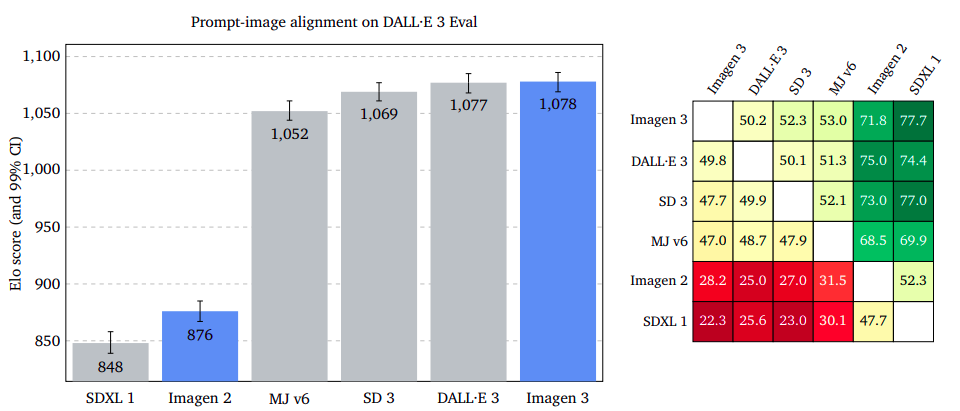
Immediate-Picture Alignment: Capturing Consumer Intent with Precision
The examine evaluates the illustration of an enter immediate in an output picture content material, ignoring potential flaws or aesthetic enchantment. Raters had been requested to decide on a picture that higher captures the immediate’s intent, disregarding totally different kinds. Outcomes confirmed Imagen 3 outperforms GenAI-Bench, DrawBench, and DALL·E 3 Eval, with overlapping confidence intervals. The examine means that ignoring potential defects or dangerous high quality in photos can enhance the accuracy of prompt-image alignment.
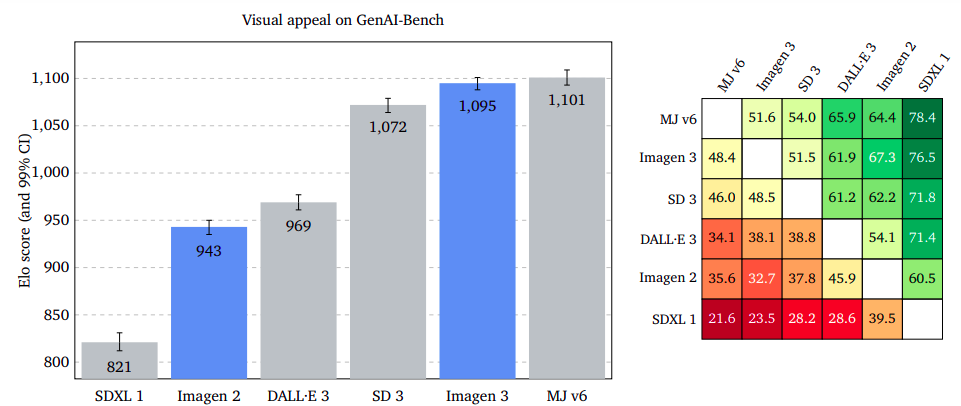
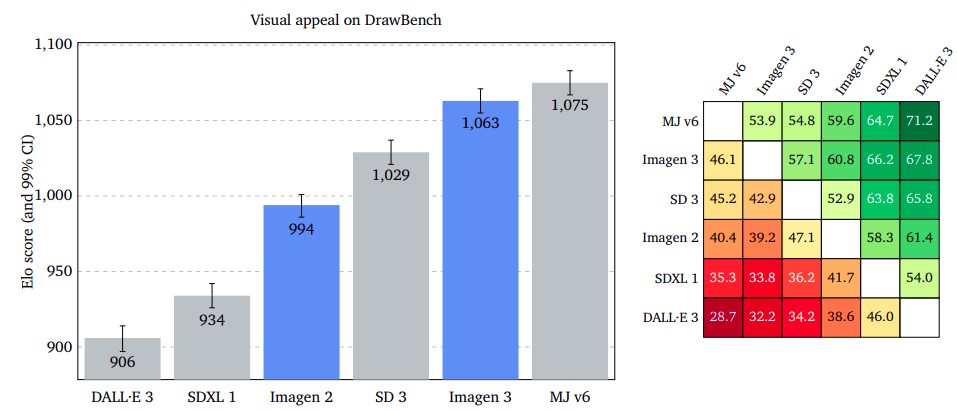
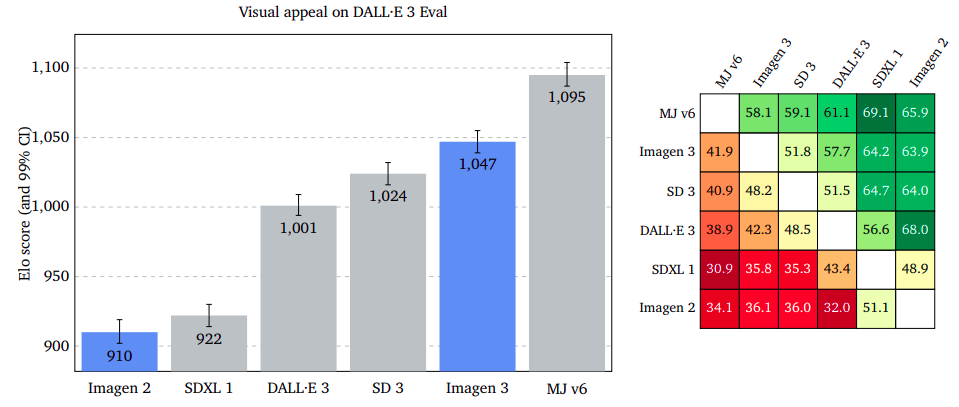
Visible Enchantment: Aesthetic Excellence Throughout Platforms
Visible enchantment measures the enchantment of generated photos, no matter content material. Raters charge two photos facet by facet with out prompts. Midjourney v6 leads, with Imagen 3 virtually on par on GenAI-Bench, barely larger on DrawBench, and a big benefit on DALL·E 3 Eval.
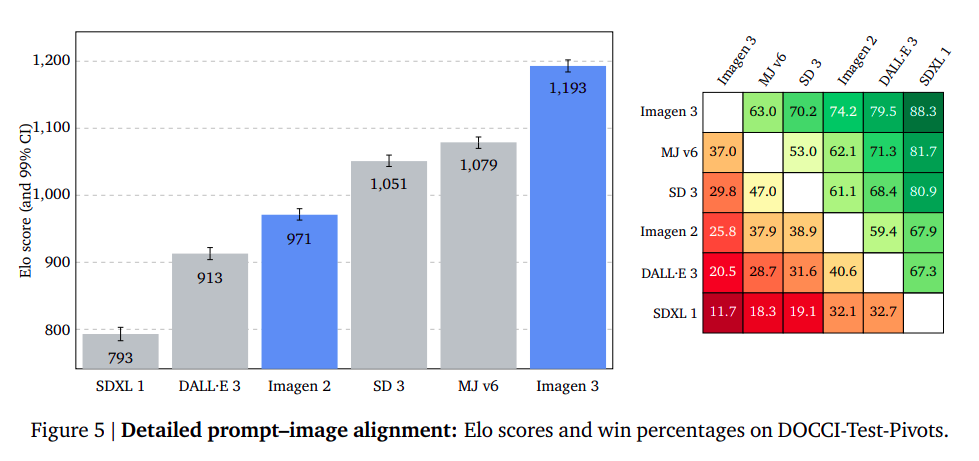
Detailed Immediate-Picture Alignment
The examine evaluates prompt-image alignment capabilities by producing photos from detailed prompts of DOCCI, that are considerably longer than earlier immediate units. The researchers discovered studying 100+ phrase prompts too difficult for human raters. As a substitute, they used high-quality captions of actual reference pictures to match the generated photos with benchmark reference photos. The raters targeted on the semantics of the pictures, ignoring kinds, capturing method, and high quality. The outcomes confirmed that Imagen 3 had a big hole of +114 Elo factors and a 63% win charge towards the second-best mannequin, highlighting its excellent capabilities in following the detailed contents of enter prompts.
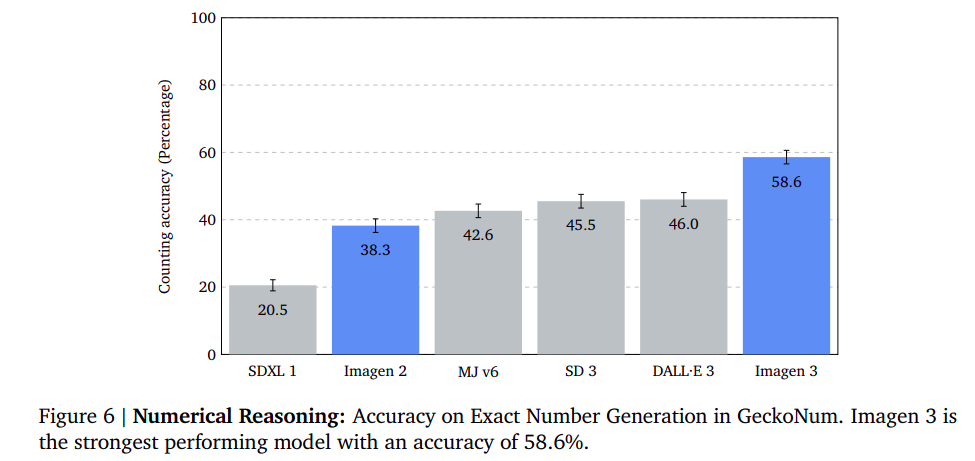
Numerical Reasoning: Outperforming the Competitors in Object Depend Accuracy
The examine evaluates the flexibility of fashions to generate a precise variety of objects utilizing the GeckoNum benchmark activity. The duty includes evaluating the variety of objects in a picture to the anticipated amount requested within the immediate. The fashions think about attributes like coloration and spatial relationships. The outcomes present that Imagen 3 is the strongest mannequin, outperforming DALL·E 3 by 12 proportion factors. It additionally has increased accuracy when producing photos containing 2-5 objects and higher efficiency on extra advanced sentence buildings.
Automated Analysis: Evaluating Fashions with CLIP, Gecko, and VQAScore
Lately, automatic-evaluation (auto-eval) metrics like CLIP and VQAScore have develop into extra broadly used to measure the standard of text-to-image fashions. This examine focuses on auto-eval metrics for immediate picture alignment and picture high quality to enrich human evaluations.
Immediate–Picture Alignment
The researchers select three robust auto-eval prompt-image alignment metrics: Contrastive twin encoders (CLIP), VQA-based (Gecko), and an LVLM prompt-based (an implementation of VQAScore2). The outcomes present that CLIP usually fails to foretell the proper mannequin ordering, whereas Gecko and VQAScore carry out properly and agree about 72% of the time. VQAScore has the sting because it matches human rankings 80% of the time, in comparison with Gecko’s 73.3%. Gecko makes use of a weaker spine, PALI, which can account for the distinction in efficiency.
The examine evaluates 4 datasets to analyze mannequin variations beneath numerous circumstances: Gecko-Rel, DOCCI-Take a look at-Pivots, Dall·E 3 Eval, and GenAI-Bench. Outcomes present that Imagen 3 persistently has the best alignment efficiency. SDXL 1 and Imagen 2 are persistently much less performant than different fashions.
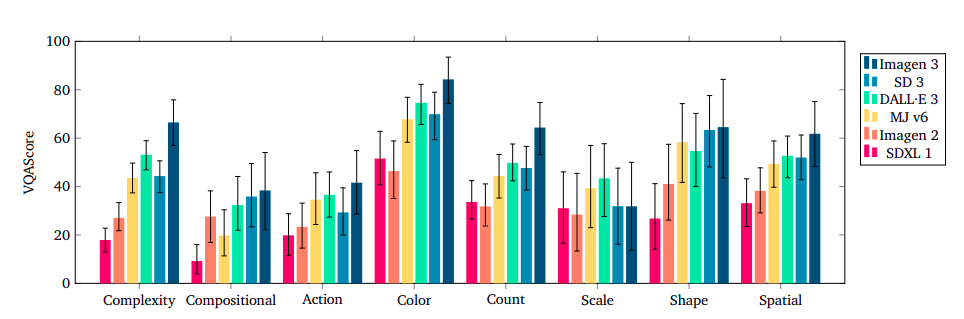
Picture High quality
Concerning picture high quality, the researchers examine the distribution of generated photos by Imagen 3, SDXL 1, and DALL·E 3 on 30,000 samples of the MSCOCO-caption validation set utilizing totally different characteristic areas and distance metrics. They observe that minimizing these three metrics is a trade-off, favoring the technology of pure colours and textures however failing to detect distortions on object shapes and components. Imagen 3 presents the decrease CMMD worth of the three fashions, highlighting its robust efficiency on state-of-the-art characteristic house metrics.
Qualitative Outcomes: Highlighting Imagen 3’s Consideration to Element
The picture under reveals 2 photos upsampled to 12 megapixels, with crops exhibiting the element degree.

Inference on Analysis
Imagen 3 is the highest mannequin in prompt-image alignment, significantly in detailed prompts and counting skills. When it comes to visible enchantment, Midjourney v6 takes the lead, with Imagen 3 coming in second. Nevertheless, it nonetheless has shortcomings in sure capabilities, equivalent to numerical reasoning, scale reasoning, compositional phrases, actions, spatial reasoning, and sophisticated language. These fashions battle with duties that require numerical reasoning, scale reasoning, compositional phrases, and actions. Total, Imagen 3 is the only option for high-quality outputs that respect person intent.
Accessing Imagen 3 through Vertex AI: A Information to Seamless Integration
Utilizing Vertex AI
To get began utilizing Vertex AI, you have to have an present Google Cloud challenge and allow the Vertex AI API. Study extra about establishing a challenge and a growth atmosphere.
Additionally, right here is the GitHub Hyperlink – Refer
import vertexai
from vertexai.preview.vision_models import ImageGenerationModel
# TODO(developer): Replace your challenge id from vertex ai console
project_id = "PROJECT_ID"
vertexai.init(challenge=project_id, location="us-central1")
generation_model = ImageGenerationModel.from_pretrained("imagen-3.0-generate-001")
immediate = """
A photorealistic picture of a cookbook laying on a wood kitchen desk, the quilt dealing with ahead that includes a smiling household sitting at an analogous desk, comfortable overhead lighting illuminating the scene, the cookbook is the principle focus of the picture.
"""
picture = generation_model.generate_images(
immediate=immediate,
number_of_images=1,
aspect_ratio="1:1",
safety_filter_level="block_some",
person_generation="allow_all",
)
Textual content rendering
Imagen 3 additionally opens up new potentialities relating to textual content rendering inside photos. Creating photos of posters, playing cards, and social media posts with captions in several fonts and colors is an effective way to experiment with this software. To make use of this operate, merely write a short description of what you want to see within the immediate. Let’s think about you need to change the quilt of a cookbook and add a title.
immediate = """
A photorealistic picture of a cookbook laying on a wood kitchen desk, the quilt dealing with ahead that includes a smiling household sitting at an analogous desk, comfortable overhead lighting illuminating the scene, the cookbook is the principle focus of the picture.
Add a title to the middle of the cookbook cowl that reads, "On a regular basis Recipes" in orange block letters.
"""
picture = generation_model.generate_images(
immediate=immediate,
number_of_images=1,
aspect_ratio="1:1",
safety_filter_level="block_some",
person_generation="allow_all",
)
Diminished latency
DeepMind presents Imagen 3 Quick, a mannequin optimized for technology velocity, along with Imagen 3, its highest-quality mannequin so far. Imagen 3 Quick is suitable for producing photos with better distinction and brightness. You’ll be able to observe a 40% discount in latency in comparison with Imagen 2. You should use the identical immediate to create two photos that illustrate these two fashions. Let’s create two options for the salad picture that we will embrace within the beforehand talked about cookbook.
generation_model_fast = ImageGenerationModel.from_pretrained(
"imagen-3.0-fast-generate-001"
)
immediate = """
A photorealistic picture of a backyard salad overflowing with colourful greens like bell peppers, cucumbers, tomatoes, and leafy greens, sitting in a wood bowl within the heart of the picture on a white marble desk. Pure mild illuminates the scene, casting comfortable shadows and highlighting the freshness of the components.
"""
# Imagen 3 Quick picture technology
fast_image = generation_model_fast.generate_images(
immediate=immediate,
number_of_images=1,
aspect_ratio="1:1",
safety_filter_level="block_some",
person_generation="allow_all",
)
immediate = """
A photorealistic picture of a backyard salad overflowing with colourful greens like bell peppers, cucumbers, tomatoes, and leafy greens, sitting in a wood bowl within the heart of the picture on a white marble desk. Pure mild illuminates the scene, casting comfortable shadows and highlighting the freshness of the components.
"""
# Imagen 3 picture technology
picture = generation_model.generate_images(
immediate=immediate,
number_of_images=1,
aspect_ratio="1:1",
safety_filter_level="block_some",
person_generation="allow_all",
)
Utilizing Gemini
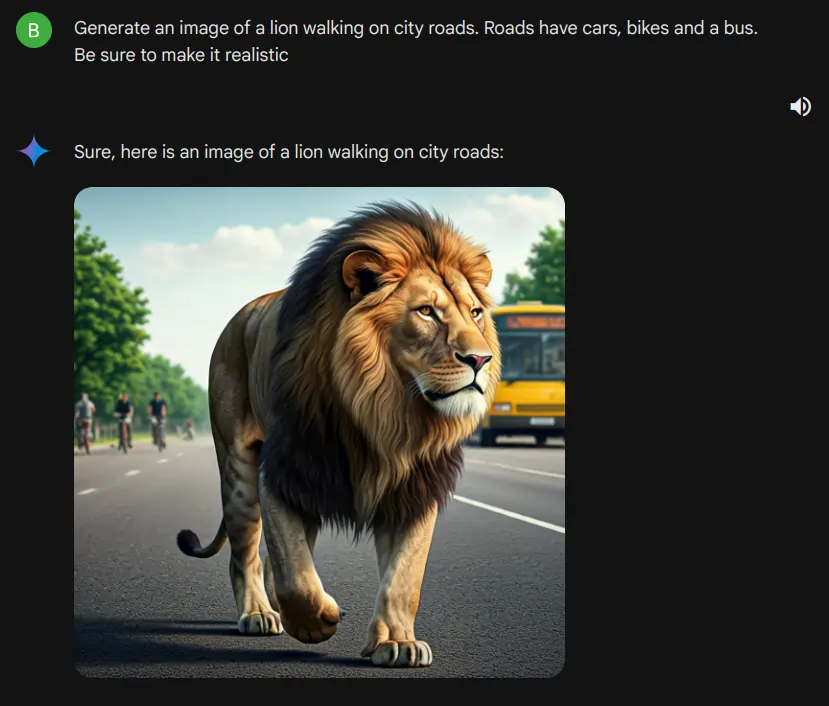
Gemini helps utilizing the brand new Imagen 3, so we’re utilizing Gemini to entry Imagen 3. Within the picture under, we will see that Gemini is producing photos utilizing Imagen 3.
Immediate – “Generate a picture of a lion strolling on metropolis roads. Roads have automobiles, bikes, and a bus. You should definitely make it practical”
Conclusion
Google’s Imagen 3 units a brand new benchmark for text-to-image synthesis, excelling in photorealism and dealing with advanced prompts with distinctive accuracy. Its robust efficiency throughout a number of analysis benchmarks highlights its capabilities in detailed prompt-image alignment and visible enchantment, surpassing fashions like DALL·E 3 and Secure Diffusion. Nevertheless, it nonetheless faces challenges in duties involving numerical and spatial reasoning. With the addition of Imagen 3 Quick for decreased latency and integration with instruments like Vertex AI, Imagen 3 opens up thrilling potentialities for inventive purposes, pushing the boundaries of multimodal AI.
In case you are on the lookout for a Generative AI course on-line, then discover – GenAI Pinnacle Program Immediately!
Steadily Requested Questions
Ans Imagen 3 excels in photorealism and complex immediate dealing with, delivering superior picture high quality and alignment with person enter in comparison with different fashions like DALL·E 3 and Secure Diffusion.
Ans. Imagen 3 is designed to handle detailed and prolonged prompts successfully, demonstrating robust efficiency in prompt-image alignment and detailed content material illustration.
Ans. The mannequin is educated on a big, numerous dataset with textual content, photos, and annotations, filtered to exclude AI-generated content material, dangerous photos, and poor-quality knowledge.
Ans. Imagen 3 Quick is optimized for velocity, providing a 40% discount in latency in comparison with the usual model whereas sustaining high-quality picture technology.
Ans. Sure, Imagen 3 can be utilized with Google Cloud’s Vertex AI, permitting seamless integration into purposes for picture technology and artistic duties.
Information science intern at Analytics Vidhya, specializing in ML, DL, and AI. Devoted to sharing insights by means of articles on these topics. Wanting to be taught and contribute to the sphere’s developments. Captivated with leveraging knowledge to resolve advanced issues and drive innovation.