We’re excited to announce that Mosaic AI Mannequin Coaching now helps the total context size of 131K tokens when fine-tuning the Meta Llama 3.1 mannequin household. With this new functionality, Databricks prospects can construct even higher-quality Retrieval Augmented Era (RAG) or software use methods through the use of lengthy context size enterprise knowledge to create specialised fashions.
The dimensions of an LLM’s enter immediate is set by its context size. Our prospects are sometimes restricted by brief context lengths, particularly in use circumstances like RAG and multi-document evaluation. Meta Llama 3.1 fashions have an extended context size of 131K tokens. For comparability, The Nice Gatsby is ~72K tokens. Llama 3.1 fashions allow reasoning over an in depth corpus of knowledge, decreasing the necessity for chunking and re-ranking in RAG or enabling extra software descriptions for brokers.
Effective-tuning permits prospects to make use of their very own enterprise knowledge to specialize present fashions. Latest strategies corresponding to Retrieval Augmented Effective-tuning (RAFT) mix fine-tuning with RAG to show the mannequin to disregard irrelevant info within the context, bettering output high quality. For software use, fine-tuning can specialize fashions to raised use novel instruments and APIs which might be particular to their enterprise methods. In each circumstances, fine-tuning at lengthy context lengths permits fashions to purpose over a considerable amount of enter info.
The Databricks Information Intelligence Platform permits our prospects to securely construct high-quality AI methods utilizing their very own knowledge. To verify our prospects can leverage state-of-the-art Generative AI fashions, you will need to help options like effectively fine-tuning Llama 3.1 on lengthy context lengths. On this weblog put up, we elaborate on a few of our latest optimizations that make Mosaic AI Mannequin Coaching a best-in-class service for securely constructing and fine-tuning GenAI fashions on enterprise knowledge.
Lengthy Context Size Effective-tuning
Lengthy sequence size coaching poses a problem primarily due to its elevated reminiscence necessities. Throughout LLM coaching, GPUs have to retailer intermediate outcomes (i.e., activations) in an effort to calculate gradients for the optimization course of. Because the sequence size of coaching examples will increase, so does the reminiscence required to retailer these activations, probably exceeding GPU reminiscence limits.
We resolve this by using sequence parallelism, the place we break up a single sequence throughout a number of GPUs. This method distributes the activation reminiscence for a sequence throughout a number of GPUs, decreasing the GPU reminiscence footprint for fine-tuning jobs and bettering coaching effectivity. Within the instance proven in Determine 1, two GPUs every course of half of the identical sequence. We use our open supply StreamingDataset’s replication function to share samples throughout teams of GPUs.
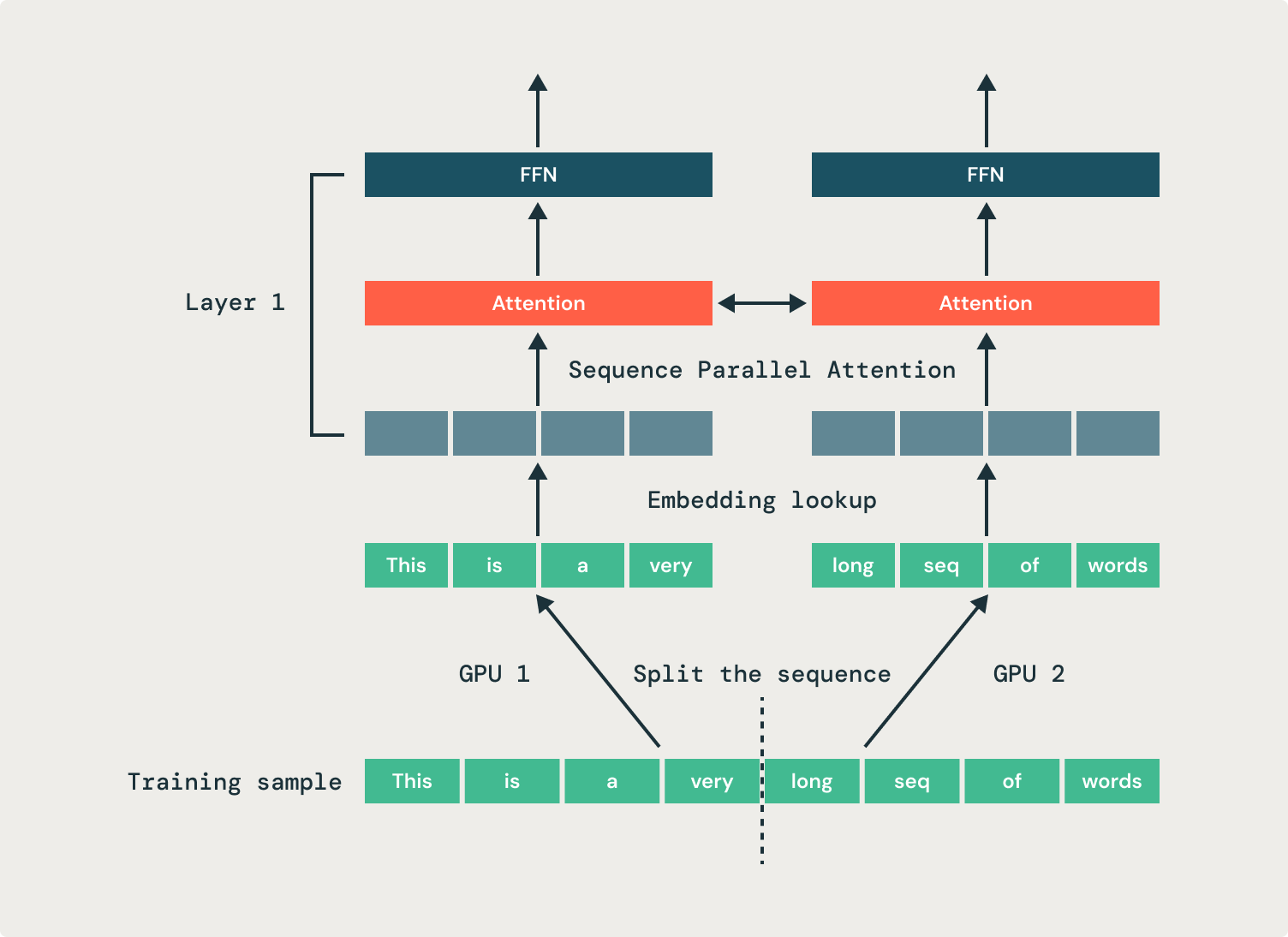
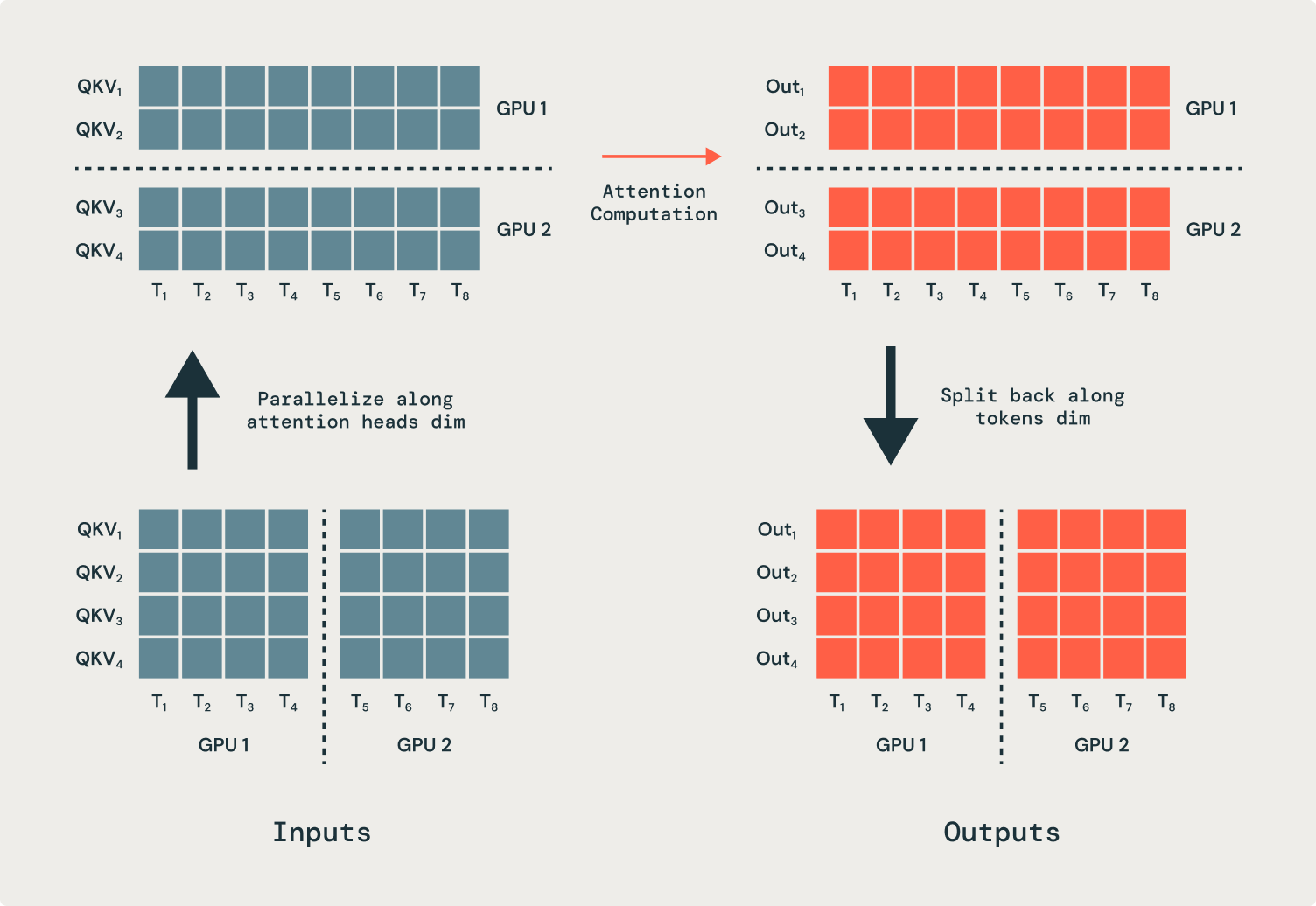
All operations in a transformer are unbiased of the sequence dimension—besides, crucially, consideration. In consequence, the eye operation must be modified to enter and output partial sequences. We parallelize consideration heads throughout many GPUs, which necessitates communication operations (all-to-alls) to maneuver tokens to the proper GPUs for processing. Previous to the eye operation, every GPU has a part of each sequence, however every consideration head should function on a full sequence. Within the instance proven in Determine 2, the primary GPU will get despatched all of the inputs for simply the primary consideration head, and the second GPU will get despatched all of the inputs for the second consideration head. After the eye operation, the outputs are despatched again to their unique GPUs.
With sequence parallelism, we’re capable of present full-context-length Llama 3.1 fine-tuning, enabling customized fashions to grasp and purpose throughout a big context.
Optimizing Effective-tuning Efficiency
Customized optimizations like sequence parallelism for fine-tuning require us to have fine-grained management over the underlying mannequin implementation. Such customization shouldn’t be doable solely with the prevailing Llama 3.1 modeling code in HuggingFace. Nevertheless, for ease of serving and exterior compatibility, the ultimate fine-tuned mannequin must be a Llama 3.1 HuggingFace mannequin checkpoint. Subsequently, our fine-tuning resolution have to be extremely optimizable for coaching, but in addition capable of produce an interoperable output mannequin.
To attain this, we convert HuggingFace Llama 3.1 fashions into an equal inside Llama illustration previous to coaching. We’ve extensively optimized this inside illustration for coaching effectivity, with enhancements corresponding to environment friendly kernels, selective activation checkpointing, efficient reminiscence use, and sequence ID consideration masking. In consequence, our inside Llama illustration permits sequence parallelism whereas yielding as much as 40% increased coaching throughput and requiring a 40% smaller reminiscence footprint. These enhancements in useful resource utilization translate to raised fashions for our prospects, because the skill to iterate shortly helps allow higher mannequin high quality.
When coaching is completed, we convert the mannequin from the inner illustration again to HuggingFace format, making certain that the saved artifact is instantly prepared for serving by way of our Provisioned Throughput providing. Determine 3 under reveals this complete pipeline.

Subsequent Steps
Get began fine-tuning Llama 3.1 at present by way of the UI or programmatically in Python. With Mosaic AI Mannequin Coaching, you’ll be able to effectively customise high-quality and open supply fashions for your online business wants, and construct knowledge intelligence. Learn our documentation (AWS, Azure) and go to our pricing web page to get began with fine-tuning LLMs on Databricks.