An improved answer-correctness choose in Agent Analysis
Agent Analysis permits Databricks clients to outline, measure, and perceive the right way to enhance the standard of agentic GenAI purposes. Measuring the standard of ML outputs takes a brand new dimension of complexity for GenAI purposes, particularly in industry-specific contexts coping with buyer knowledge: the inputs could comprise complicated open-ended questions, and the outputs may be long-form solutions that can not be simply in comparison with reference solutions utilizing string-matching metrics.
Agent Analysis solves this drawback with two complementary mechanisms. The primary is a built-in evaluate UI that enables human subject-matter specialists judges to speak with completely different variations of the appliance and supply suggestions on the generated responses. The second is a collection of built-in LLM judges that present automated suggestions and may thus scale up the analysis course of to a a lot bigger variety of take a look at instances. The built-in LLM judges can motive in regards to the semantic correctness of a generated reply with respect to a reference reply, whether or not the generated reply is grounded on the retrieved context of the RAG agent, or whether or not the context is enough to generate the right reply, to call just a few examples. A part of our mission is to repeatedly enhance the effectiveness of those judges in order that Agent Analysis clients can deal with extra superior use instances and be extra productive in enhancing the standard of their purposes.
In step with this mission, we’re glad to announce the launch of an improved answer-correctness choose in Agent Analysis. Reply-correctness evaluates how a generated reply to an enter query compares to a reference reply, offering an important and grounded metric for measuring the standard of an agentic software. The improved choose gives vital enhancements in comparison with a number of baselines, particularly on buyer consultant use instances.
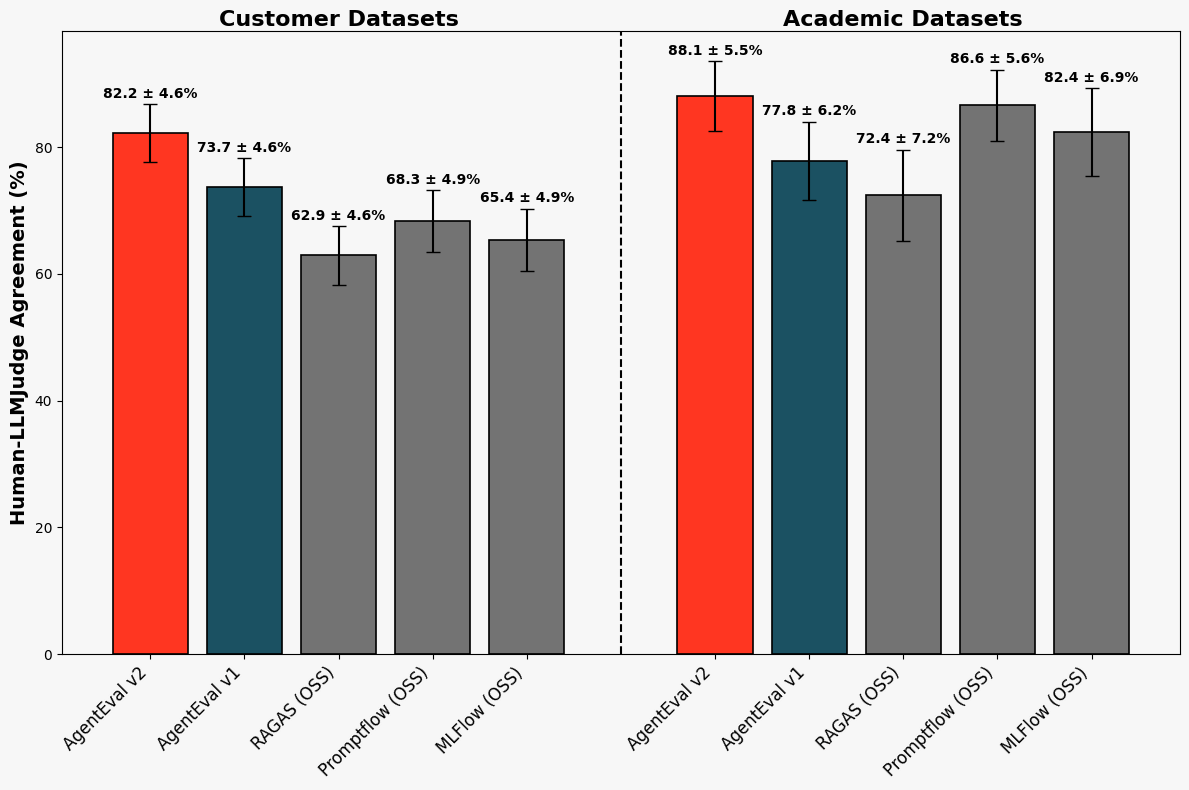
Determine 1. Settlement of recent answer-correctness choose with human raters: Every bar reveals the share of settlement between the choose and human labelers for the correctness of a solution, as measured on our benchmark datasets. AgentEval v2 represents the brand new choose that we now have launched with a big enchancment on buyer datasets.

Determine 2. Inter-annotator reliability (Cohen’s kappa) between the answer-correctness judges and human raters: Every bar reveals the worth of Cohen’s kappa between the choose and human labelers for the correctness of a solution, as measured on our benchmark datasets. Values nearer to 1 point out that settlement between the choose and human raters is due much less to probability. AgentEval v2 represents the brand new choose that we now have launched.
The improved choose, which is the results of an lively collaboration between the analysis and engineering groups in Mosaic AI, is routinely out there to all clients of Agent Analysis. Learn on to study in regards to the high quality enhancements of the brand new choose and our methodology for evaluating the effectiveness of LLM judges usually. You can even take a look at drive Agent Analysis in our demo pocket book.
How? The Information and Simply the Information
The reply-correctness choose receives three fields as enter: a query, the reply generated by the appliance for this query, and a reference reply. The choose outputs a binary outcome (“Sure”/”No”) to point whether or not the generated reply is enough when put next with the reference reply, together with a rationale that explains the reasoning. This offers the developer a gauge of agent high quality (as a proportion of “Sure” judgements over an analysis set) in addition to an understanding of the reasoning behind particular person judgements.
Based mostly on a examine of customer-representative use instances and our baseline programs, we now have discovered {that a} key limitation within the effectiveness of many current LLM judges is that they depend on grading rubrics that use a comfortable notion of “similarity” and thus allow substantial ambiguity of their interpretation. Particularly, whereas these judges could also be efficient for typical educational datasets with quick solutions, they will current challenges for customer-representative use instances the place solutions are sometimes lengthy and open-ended. In distinction, our new LLM choose in Agent Analysis causes on the extra narrowly outlined stage of details and claims in a generated response.
Buyer-Consultant Use Instances. The analysis of LLM judges in the neighborhood is usually grounded on well-tested, educational query answering datasets, comparable to NQ and HotPotQA. A salient future of those datasets is that the questions have quick, extractive factual solutions comparable to the next:

Instance 1: Query and reference reply from educational benchmarks: The query is often concrete and has a single and quick factual reply.
Whereas these datasets are well-crafted and well-studied, a lot of them have been developed previous to current improvements in LLMs and usually are not consultant of buyer use instances, specifically, open-ended questions with solutions which are multi-part or have completely different a number of acceptable solutions of various elaboration. For instance,

Instance 2: Query and reference/generated reply from customer-representative use instances: The query may be open-ended and the solutions comprise a number of elements. There may additionally be a number of acceptable solutions.
Rubric Ambiguity. LLM judgements usually observe a rubric-based strategy, however designing a broadly relevant rubric presents a problem. Specifically, such general-purpose rubrics usually introduce obscure phrasing, which makes their interpretation ambiguous. For instance, the next rubrics drive the PromptFlow and MLFlow LLM judges:

OSS PromptFlow immediate for reply correctness

OSS MLFlow immediate for reply correctness
These rubrics are ambiguous as to 1) what similarity means, 2) the important thing options of a response to floor a similarity measurement, in addition to 3) the right way to calibrate the power of similarity in opposition to the vary of scores. For solutions with vital elaboration past the extractive solutions in educational datasets, we (together with others [1]), have discovered that this ambiguity can result in many situations of unsure interpretation for each people and LLMs when they’re tasked with labeling a response with a rating.
Reasoning in regards to the Information. Our strategy in Agent Analysis as a substitute takes inspiration from leads to the analysis neighborhood on protocols for assessing the correctness of long-form solutions by reasoning about primitive details and claims in a bit of textual content [2, 1, 3] and leveraging the capabilities of language fashions to take action [4, 5, 6]. As an example, within the reference reply in Instance 2 above, there are 4 implied claims:
- Leveraging Databricks’ MLflow for mannequin monitoring is an efficient technique.
- Utilizing managed clusters for scalability is an efficient technique.
- Optimizing knowledge pipelines is an efficient technique.
- Integrating with Delta Lake for knowledge versioning is an efficient technique.
Agent Analysis’s LLM Choose strategy evaluates the correctness of a generated reply by confirming that the generated reply consists of the details and claims from the reference reply; by inspection, the generated reply in Instance 2 is an accurate reply as a result of it consists of all aforementioned implied claims.
Total, evaluating the inclusion of details is a way more slender and particular process than figuring out if the generated reply and reference reply are “comparable.” Our enchancment over these different approaches on customer-representative use instances demonstrates the advantages of our strategy.
Analysis Methodology
We consider our new answer-correctness choose on a set of educational datasets, together with HotPotQA and Pure Questions, and to focus on the sensible advantages of the brand new LLM choose, we additionally use an inside benchmark of datasets donated by our clients that mannequin particular use instances in industries like finance, documentation, and HR. (Be happy to succeed in out to [email protected] In case you are a Databricks buyer and also you wish to assist us enhance Agent Analysis on your use instances .)
For every (query, generated reply, reference reply) triplet within the educational and {industry} datasets, we ask a number of human labelers to fee the correctness of the generated reply after which receive an aggregated label via majority voting, excluding any examples for which there isn’t a majority. To evaluate the standard of the aggregated label, we study the diploma of inter-rater settlement and in addition the skew of the label distribution (a skewed distribution can lead to settlement by probability). We quantify the previous via Krippendorf’s alpha. The ensuing worth (0.698 for educational datasets, 0.565 for {industry} datasets) signifies that there’s good settlement amongst raters. The skew can be low sufficient (72.7% “sure” / 23.6% “no” in educational datasets, 52.4% “sure” / 46.6% “no” in {industry} datasets) so it isn’t possible that this settlement occurs at random.
We measure our LLM choose’s efficiency with respect to human labelers on two key metrics: proportion settlement and Cohen’s kappa. Share settlement measures the frequency of settlement between the LLM choose and human labelers, offering an easy measure of accuracy. Cohen’s kappa, starting from -1 to 1, captures the prospect settlement among the many LLM choose and human raters. A Cohen’s kappa worth nearer to 1 signifies that the settlement isn’t by probability and is thus a sturdy sign for the non-random accuracy of an LLM choose. We compute confidence intervals for each metrics by operating every benchmark thrice (to account for non-determinism within the underlying LLMs) after which establishing bootstrapped intervals with a 95% confidence stage.
Efficiency Outcomes
Figures 1 and a pair of above current the outcomes of our analysis. On educational datasets, the brand new choose reported 88.1 ± 5.5% settlement and Cohen’s kappa scores of 0.64 ± 0.13, showcasing a powerful settlement with human labelers. Our LLM choose maintained sturdy efficiency on {industry} datasets, attaining 82.2 ± 4.6% settlement and Cohen’s kappa scores of 0.65 ± 0.09, highlighting substantial non-random settlement.
Moreover, we in contrast our new choose to current AnswerCorrectness choose baselines, beginning with the earlier iteration of our inside choose (which we denote as Agent Analysis v1). We additionally in contrast it to the next open-source baselines: RAGAS (semantic similarity scoring), OSS PromptFlow (five-star ranking system), OSS MLFlow (five-point scoring system). We discovered that our choose persistently achieved the very best labeler-LLM choose settlement and Cohen’s kappa throughout each educational and buyer datasets. On buyer datasets, our choose improved the prevailing Agent Analysis choose and outperformed the following closest open-source baseline by 13-14% in settlement and 0.27 in Cohen’s kappa, whereas sustaining a lead of 1-2% in settlement and 0.06 in Cohen’s kappa on educational datasets.
Notably, a few of these baseline judges used few-shot settings the place the choose is introduced with examples of judgements with actual knowledge labels inside the immediate, whereas our choose was evaluated in a zero-shot setting. This highlights the potential of our choose to be additional optimized with few-shot studying, attaining even greater efficiency. Agent Analysis already helps this performance and we’re actively working to enhance the choice of few-shot examples within the subsequent model of our product.
Subsequent Steps
As talked about earlier, the improved choose is routinely enabled for all clients of Agent Analysis. We have now used DSPy to discover the area of designs for our choose and, following on that work, we’re actively engaged on additional enhancements to this choose.
- Take a look at our instance pocket book (AWS | Azure) for a fast demonstration of Agent Analysis and the built-in judges.
- Documentation for Agent Analysis (AWS | Azure).
- Attain out to [email protected] in case you are a Databricks buyer and also you wish to assist enhance the product on your use case by donating analysis datasets.
- Attend the following Databricks GenAI Webinar on 10/8: The shift to Information Intelligence.