Introduction
Giant Language Fashions (LLMs) contributed to the progress of Pure Language Processing (NLP), however additionally they raised some essential questions on computational effectivity. These fashions have turn out to be too giant, so the coaching and inference price is not inside affordable limits.
To deal with this, the Chinchilla Scaling Regulation, launched by Hoffmann et al. in 2022, gives a groundbreaking framework for optimizing the coaching of LLMs. The Chinchilla Scaling Regulation affords a vital information to effectively scaling LLMs with out compromising efficiency by establishing relationships between mannequin dimension, coaching information, and computational assets. We’ll talk about it intimately on this article.

Overview
- The Chinchilla Scaling Regulation optimizes LLM coaching by balancing mannequin dimension and information quantity for enhanced effectivity.
- New scaling insights recommend that smaller language fashions like Chinchilla can outperform bigger ones when educated on extra information.
- Chinchilla’s method challenges conventional LLM scaling by prioritizing information amount over mannequin dimension for compute effectivity.
- The Chinchilla Scaling Regulation affords a brand new roadmap for NLP, guiding the event of high-performing, resource-efficient fashions.
- The Chinchilla Scaling Regulation maximizes language mannequin efficiency with minimal compute prices by doubling the mannequin dimension and coaching information.
What’s Chinchilla Scaling Regulation?
The paper “Coaching Compute-Optimum Giant Language Fashions,” revealed in 2022, focuses on figuring out the connection between three key components: mannequin dimension, variety of tokens, and compute price range. The authors discovered that present giant language fashions (LLMs) like GPT-3 (175B parameters), Gopher (280B), and Megatron (530B) are considerably undertrained. Whereas these fashions elevated in dimension, the quantity of coaching information remained largely fixed, resulting in suboptimal efficiency. The authors suggest that mannequin dimension and the variety of coaching tokens should be scaled equally for compute-optimal coaching. To show this, they educated round 400 fashions, starting from 70 million to over 16 billion parameters, utilizing between 5 and 500 billion tokens.
Based mostly on these findings, the authors educated a brand new mannequin referred to as Chinchilla, which makes use of the identical compute price range as Gopher (280B) however with solely 70B parameters and 4 occasions extra coaching information. Chinchilla outperformed a number of well-known LLMs, together with Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), and Megatron (530B). This outcome contradicts the scaling legal guidelines proposed by OpenAI in “Scaling Legal guidelines for LLMs,” which recommended that bigger fashions would at all times carry out higher. The Chinchilla Scaling Legal guidelines display that smaller fashions when educated on extra information, can obtain superior efficiency. This method additionally makes smaller fashions simpler to fine-tune and reduces inference latency.
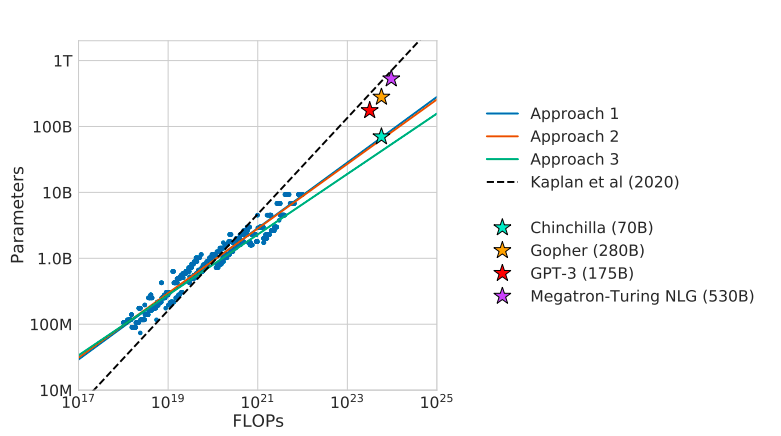
The graph reveals that, regardless of being smaller, Chinchilla (70B) follows a distinct compute-to-parameter ratio and outperforms bigger fashions like Gopher and GPT-3.
The opposite approaches (1, 2, and three) discover other ways to optimize mannequin efficiency primarily based on compute allocation.
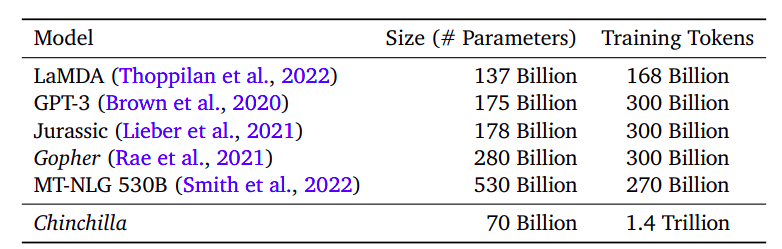
From this determine we are able to see Chinchilla’s Benefit though Chinchilla is smaller in dimension (70B parameters), it was educated on a a lot bigger dataset (1.4 trillion tokens), which follows the precept launched within the Chinchilla Scaling Legal guidelines—smaller fashions can outperform bigger ones if they’re educated on extra information.Different fashions like Gopher, GPT-3, and MT-NLG 530B have considerably extra parameters however had been educated on comparatively fewer tokens, suggesting that these fashions might not have totally optimized their compute potential.
A Shift in Focus: From Mannequin Dimension to Information
Traditionally, the main target in enhancing LLM efficiency has been on rising mannequin dimension, as seen in fashions like GPT-3 and Gopher. This was pushed by the analysis of Kaplan et al. (2020), which proposed a power-law relationship between mannequin dimension and efficiency. Nevertheless, as fashions grew bigger, the quantity of coaching information didn’t scale accordingly, leading to underutilized compute potential. The Chinchilla Scaling Legal guidelines problem this by exhibiting {that a} extra balanced allocation of assets, notably when it comes to information and mannequin dimension, can result in compute-optimal fashions that carry out higher with out reaching their lowest attainable loss.
Overview of the Chinchilla Scaling Regulation
The trade-off between mannequin dimension, coaching tokens, and computational price is on the core of the Chinchilla Scaling Regulation. The regulation establishes a compute-optimal stability between these three parameters:
- Mannequin Dimension (N): The variety of parameters within the mannequin.
- Coaching Tokens (D): The entire variety of tokens used throughout coaching.
- Computational Value (C): The entire compute assets allotted for coaching, often measured in FLOPs (floating level operations per second).
The Chinchilla Scaling Regulation means that for optimum efficiency, each mannequin dimension and the quantity of coaching information ought to scale at equal charges. Particularly, the variety of coaching tokens also needs to double for each doubling of mannequin dimension. This method contrasts earlier strategies, which emphasised rising mannequin dimension with out sufficiently rising the coaching information.
This relationship is mathematically expressed as:

The place:
- L is the mannequin’s closing loss.
- L_0 is the irreducible loss, representing the very best efficiency.
- A and B are constants that seize the mannequin’s underperformance in comparison with a great generative course of.
- α and β are exponents that describe how loss scales with respect to mannequin dimension and information dimension, respectively.
Key Findings of the Chinchilla Scaling Regulation
Listed here are the important thing findings of the Chinchilla scaling regulation:
Compute-Optimum Coaching
The Chinchilla Scaling Regulation highlights an optimum stability between mannequin dimension and the quantity of coaching information. Particularly, the examine discovered that an approximate ratio of 20 coaching tokens per mannequin parameter is good for attaining one of the best efficiency with a given compute price range. For instance, the Chinchilla mannequin, with 70 billion parameters, was educated on 1.4 trillion tokens—4 occasions greater than Gopher however with far fewer parameters. This stability resulted in a mannequin considerably outperforming bigger fashions on a number of benchmarks.
Empirical Proof from Over 400 Fashions
To derive the Chinchilla Scaling Legal guidelines, Hoffmann et al. educated over 400 transformer fashions, ranging in dimension from 70 million to 16 billion parameters, on datasets of as much as 500 billion tokens. The empirical proof strongly supported the speculation that fashions educated with extra information (at a hard and fast compute price range) carry out higher than merely rising mannequin dimension alone.
Revised Estimates and Steady Enchancment
Subsequent analysis has sought to refine Hoffmann et al.’s preliminary findings, figuring out attainable changes within the parameter estimates. Some research have recommended minor inconsistencies within the authentic outcomes and have proposed revised estimates to suit the noticed information higher. These changes point out that additional analysis is required to grasp the dynamics of mannequin scaling totally, however the core insights of the Chinchilla Scaling Regulation stay a beneficial guideline.
Advantages of the Chinchilla Method
Listed here are the advantages of the Chinchilla method:
Improved Efficiency
Chinchilla’s equal scaling of mannequin dimension and coaching information yielded outstanding outcomes. Regardless of being smaller than many different giant fashions, Chinchilla outperformed GPT-3, Gopher, and even the huge Megatron-Turing NLG mannequin (530 billion parameters) on varied benchmarks. As an example, on the Huge Multitask Language Understanding (MMLU) benchmark, Chinchilla achieved a median accuracy of 67.5%, a big enchancment over Gopher’s 60%.
Decrease Computational Prices
The Chinchilla method optimizes efficiency and reduces computational and vitality prices for coaching and inference. Coaching fashions like GPT-3 and Gopher require monumental computing assets, making their use in real-world functions prohibitively costly. In distinction, Chinchilla’s smaller mannequin dimension and extra intensive coaching information end in decrease compute necessities for fine-tuning and inference, making it extra accessible for downstream functions.
Implications for Future Analysis and Mannequin Growth
The Chinchilla Scaling Legal guidelines provide beneficial insights for the way forward for LLM growth. Key implications embrace:
- Guiding Mannequin Design: Understanding how you can stability mannequin dimension and coaching information permits researchers and builders to make extra knowledgeable choices when designing new fashions. By adhering to the ideas outlined within the Chinchilla Scaling Regulation, builders can be certain that their fashions are each compute-efficient and high-performing.
- Guiding Mannequin Design: Information on optimizing the quantity and so the coaching information informs the fashions’ analysis and design. Inside this guideline scale, the event of their concepts will function inside broad definitions of excessive effectivity with out extreme consumption of pc assets.
- Efficiency Optimization: The Chinchilla Scaling Regulation gives a roadmap for optimizing LLMs. By specializing in equal scaling, builders can keep away from the pitfalls of under-training giant fashions and be certain that fashions are optimized for coaching and inference duties.
- Exploration Past Chinchilla: As analysis continues, new methods are rising to increase the concepts of the Chinchilla Scaling Regulation. For instance, some researchers are investigating methods to attain related efficiency ranges with fewer computational assets or to additional improve mannequin efficiency in data-constrained environments. These explorations are prone to end in much more environment friendly coaching pipelines.
Challenges and Concerns
Whereas the Chinchilla Scaling Regulation marks a big step ahead in understanding LLM scaling, it additionally raises new questions and challenges:
- Information Assortment: As was the case for Chinchilla, coaching a mannequin with 1.4 trillion tokens implies the provision of many high-quality datasets. Nevertheless, such a scale of knowledge assortment and processing raises organizational issues for researchers and builders, in addition to moral issues, equivalent to privateness and bias.
- Bias and Toxicity: Nevertheless, proportional discount of normal bias and toxicity of a mannequin educated utilizing the Chinchilla Scaling regulation is simpler and extra environment friendly than all these inefficiency points. As LLMs develop in energy and attain, making certain equity and mitigating dangerous outputs might be essential focus areas for future analysis.
Conclusion
The Chinchilla Scaling Regulation represents a pivotal development in our understanding of optimizing the coaching of huge language fashions. By establishing clear relationships between mannequin dimension, coaching information, and computational price, the regulation gives a compute-optimal framework for effectively scaling LLMs. The success of the Chinchilla mannequin demonstrates the sensible advantages of this method, each when it comes to efficiency and useful resource effectivity.
As analysis on this space continues, the ideas of the Chinchilla Scaling Regulation will possible form the way forward for LLM growth, guiding the design of fashions that push the boundaries of what’s attainable in pure language processing whereas sustaining sustainability and accessibility.
Additionally, in case you are on the lookout for a Generative AI course on-line, then discover: the GenAI Pinnacle Program!
Steadily Requested Questions
Ans. The Chinchilla scaling regulation is an empirical framework that describes the optimum relationship between the dimensions of a language mannequin (variety of parameters), the quantity of coaching information (tokens), and the computational assets required for coaching. It goals to attenuate coaching compute whereas maximizing mannequin efficiency.
Ans. The important thing parameters embrace:
1. N: Variety of parameters within the mannequin.
2. D: Variety of coaching tokens.
3. C: Complete computational price in FLOPS.
4. L: Common loss achieved by the mannequin on a take a look at dataset.
5. A and B: Constants reflecting underperformance in comparison with a great generative course of.
6. α and β: Exponents describing how loss scales regarding mannequin and information dimension, respectively.
Ans. The regulation means that each mannequin dimension and coaching tokens ought to scale at equal charges for optimum efficiency. Particularly, for each doubling of mannequin dimension, the variety of coaching tokens also needs to double, sometimes aiming for a ratio of round 20 tokens per parameter.
Ans. Current research have indicated potential points with Hoffmann et al.’s authentic estimates, together with inconsistencies in reported information and overly tight confidence intervals. Some researchers argue that the scaling regulation could also be too simplistic and doesn’t account for varied sensible concerns in mannequin coaching.
Ans. The findings from the Chinchilla scaling regulation have knowledgeable a number of notable fashions’ design and coaching processes, together with Google’s Gemini suite. It has additionally prompted discussions about “past Chinchilla” methods, the place researchers discover coaching fashions bigger than optimum in line with the unique scaling legal guidelines.
Hello I’m Janvi Kumari at the moment a Information Science Intern at Analytics Vidhya, captivated with leveraging information for insights and innovation. Curious, pushed, and wanting to study. If you would like to attach, be at liberty to succeed in out to me on LinkedIn