Introduction
In case you’ve labored with Massive Language Fashions (LLMs), you’re probably accustomed to the challenges of tuning them to reply exactly as desired. This battle usually stems from the fashions’ restricted reasoning capabilities or issue in processing advanced prompts. Regardless of being educated on huge datasets, LLMs can falter with nuanced or context-heavy queries, resulting in frustration amongst builders. The core problem is to steadiness the mannequin’s generalization with the necessity for particular, correct responses.
LLMs have certainly made outstanding advances in pure language processing, enabling them to generate human-like textual content, have interaction in conversations, and even help with decision-making. However, their logical reasoning skills—reminiscent of drawback decomposition, cause-and-effect understanding, and sustaining consistency—nonetheless have room for progress. Improved reasoning is important for duties like scientific analysis and strategic planning, the place output precision and coherence are essential. It’s evident how vital it’s to boost reasoning in LLMs, noting that it’s essential for functions requiring advanced problem-solving, decision-making, and understanding of cause-and-effect relationships. This text talks all about how we are able to enhance the reasoning capabilities of LLMs by way of Immediate Engineering, and it’s primarily based on the latest talks by Anant Agarwal on the Knowledge Hack Summit 2024, which targeted on Enhancing Logical Reasoning in LLMs By Immediate Engineering.

Overview
- Immediate engineering is a strong software for enhancing LLM reasoning with out in depth retraining.
- Chain of Thought (CoT) prompting is a key method for guiding LLMs by way of step-by-step reasoning.
- Least to Most Successive Prompting successfully breaks down advanced issues for LLMs to unravel sequentially.
- Step-back Prompting encourages LLMs to think about high-level ideas earlier than diving into particular issues.
- Interleaved Retrieval with CoT Prompting combines info retrieval with reasoning for extra complete responses.
Why Reasoning is Necessary for LLMs?
Reasoning is taken into account a cornerstone of intelligence. Whereas LLMs excel at many duties, their reasoning capacity is essential for functions requiring advanced problem-solving, decision-making, and understanding of cause-and-effect relationships. Improved reasoning capabilities can result in extra dependable and reliable AI methods throughout varied domains. Right here’s why reasoning capabilities are very important for LLMs:
- Complicated Drawback Fixing: Reasoning permits LLMs to interrupt down and resolve advanced, multi-step issues extra successfully.
- Resolution Making: Logical reasoning is crucial for making knowledgeable choices, significantly in fields like strategic planning and medical analysis.
- Understanding Causality: It helps LLMs grasp cause-and-effect relationships, which is vital for predicting outcomes and analyzing occasions.
- Improved Explanations: Reasoning permits LLMs to offer clear, logical explanations, enhancing transparency and consumer belief.
- Dealing with Ambiguity: LLMs with robust reasoning can navigate ambiguous knowledge and queries, providing extra dependable responses.
- Generalization: Reasoning aids in making use of discovered information to new conditions, bettering the flexibility of LLMs.
- Reality-Checking and Consistency: It helps preserve inside consistency and accuracy, lowering contradictions or misinformation.
- Moral Issues: Sturdy reasoning permits LLMs to navigate moral dilemmas, essential as AI integrates extra into decision-making.
- Scientific and Mathematical Purposes: It’s essential for fixing logical proofs and equations in fields like math and science.
- Artistic Drawback Fixing: Reasoning fosters creativity by enabling LLMs to mix concepts logically in novel methods.
- Improved Human-AI Interplay: LLMs with good reasoning abilities can have interaction in additional significant, context-aware dialogues with people.
- Robustness In opposition to Adversarial Inputs: Higher reasoning makes LLMs extra resilient towards deceptive or adversarial inputs.
Enhancing reasoning in LLMs results in extra highly effective, versatile, and reliable AI methods that higher perceive and work together with the world, carefully resembling human cognition.
Additionally learn: What are Massive Language Fashions(LLMs)?
Limitations of LLMs in Reasoning
LLMs are educated as next-token prediction fashions, not as devoted reasoning engines. This basic structure can restrict their capacity to carry out advanced logical operations, particularly when confronted with multi-step issues or duties requiring the mixing of a number of items of data. Understanding these limitations is essential for creating efficient methods to boost their reasoning capabilities. Right here’s an in-depth take a look at the important thing limitations:
Subsequent-Token Prediction Structure
- LLMs are essentially designed as next-token prediction fashions, not as devoted reasoning engines.
- This structure can result in difficulties in sustaining long-term coherence and logical consistency throughout prolonged reasoning chains.
- The fashions might battle to backtrack or revise earlier steps in a reasoning course of, primarily specializing in producing the following most possible token.
Lack of Causal Understanding
- LLMs usually battle to differentiate correlation from causation.
- They could generate plausible-sounding however logically flawed explanations for phenomena, as they don’t perceive cause-and-effect relationships.
Problem with Summary Reasoning
- Whereas LLMs excel at sample recognition inside their coaching knowledge, they usually battle with summary reasoning duties that require generalization past their coaching examples.
- This may result in difficulties in fixing novel issues or making use of discovered ideas to unfamiliar contexts.
Inconsistency in Multi-Step Reasoning
- LLMs might carry out nicely within the preliminary steps of a reasoning course of however lose coherence or introduce contradictions in later steps.
- They usually lack a worldwide “understanding” of all the reasoning chain, resulting in regionally believable however globally inconsistent conclusions.
Vulnerability to Biases and Spurious Correlations
- LLMs can decide up and amplify biases current of their coaching knowledge.
- They could depend on superficial patterns or spurious correlations somewhat than deep, logical reasoning.
Problem with Quantitative Reasoning
- Many LLMs battle with exact numerical calculations or mathematical proofs.
- They could present approximations or qualitative solutions the place actual quantitative reasoning is required.
Regardless of their huge information, they usually battle with commonsense reasoning, lacking easy logical implications because of an absence of real-world grounding. LLMs can even generate inaccurate info with excessive confidence, a phenomenon referred to as hallucination, resulting in false logical conclusions. Context size limitations additional hinder their reasoning capabilities, limiting their capacity to take care of consistency over lengthy passages or advanced issues. Moreover, LLMs usually battle with duties requiring formal symbolic manipulation, reminiscent of superior arithmetic or logic, and sometimes fail when reasoning about negations or hypothetical eventualities.
In contrast to human reasoners, they can not independently search out extra info and are restricted to the information of their coaching knowledge and supplied prompts. Moreover, LLMs lack meta-cognitive skills, that means they can not assess their very own reasoning processes or acknowledge logical errors. These limitations spotlight the significance of ongoing analysis and growth to boost the reasoning capabilities of LLMs, together with enhancements in immediate engineering, mannequin structure, and the mixing of hybrid methods.
Additionally Learn: Newbie’s Information to Construct Massive Language Fashions from Scratch
Present benchmarks to measure LLM reasoning capabilities

Massive language fashions (LLMs) usually appear to retailer intelligence, however they battle to motive out easy issues like people do. In contrast to people, LLMs solely motive successfully when supplied with the best context. This limitation arises from their design: they primarily function next-token prediction fashions somewhat than reasoning engines. Regardless of this, LLMs carry out virtually magical duties, demonstrating skills past their meant design. As mannequin measurement will increase, reasoning in LLMs turns into extra evident, rising as a functionality. Smaller fashions battle with reasoning duties, so fine-tuning bigger fashions is more practical than smaller ones utilizing methods like LoRA (Low-Rank Adaptation) or FLORA (High quality-tuning LLMs with LoRA). (Wei et al., 2022). Leveraging bigger fashions is usually really helpful for duties that demand superior reasoning. Researchers assess LLMs’ reasoning skills by way of a number of established benchmarks.
A number of benchmarks have been developed to evaluate the reasoning capabilities of LLMs:
- ARC Problem: A multi-part Science query process with various issue ranges (straightforward and superior questions). Right here, LLMs are noticed responding to those challenges with out offering any examples.
- HellaSwag: It checks commonsense reasoning skills. Right here, LLMs are given easy duties that people inherently can reply, however we test their capabilities to know the context.
- Grade Faculty Math Issues (GSM8K): An 8,000-question benchmark for grade faculty math issues.
- Discrete Reasoning over Paragraphs (DROP): A studying comprehension dataset with 96,000 questions requiring multi-step reasoning.
Word: All of the strategies we clarify shall be applied utilizing the annotated DROP dataset in LangChain supplied by Dua et al. To run the code, you solely want the HuggingFace API Token.
Immediate Engineering for Improved Reasoning
Immediate engineering has emerged as a strong method to boost the reasoning capabilities of LLMs with out the necessity for fine-tuning or retraining.
Right here’s a comparability between Commonplace Prompting and Chain of Thought (CoT) Prompting primarily based on the transcript supplied:
Commonplace Prompting
- Method: In customary prompting, the mannequin is given a single instance or instruction, anticipating it to offer the right reply instantly.
- Instance Supplied: The transcript mentions a easy drawback the place “Roger has 5 tennis balls and buys two extra cans of tennis balls, every can containing three balls.” The usual immediate asks, “What number of tennis balls does Roger have?” The anticipated reply is 11.
- Challenge: The mannequin (GPT-3.5 on this case) struggles to reply a subsequent, equally structured query appropriately. This highlights a limitation in reasoning or understanding the issue with out additional steering.
- Consequence: Commonplace prompting usually fails in additional advanced reasoning duties as a result of it doesn’t information the mannequin by way of the reasoning course of.
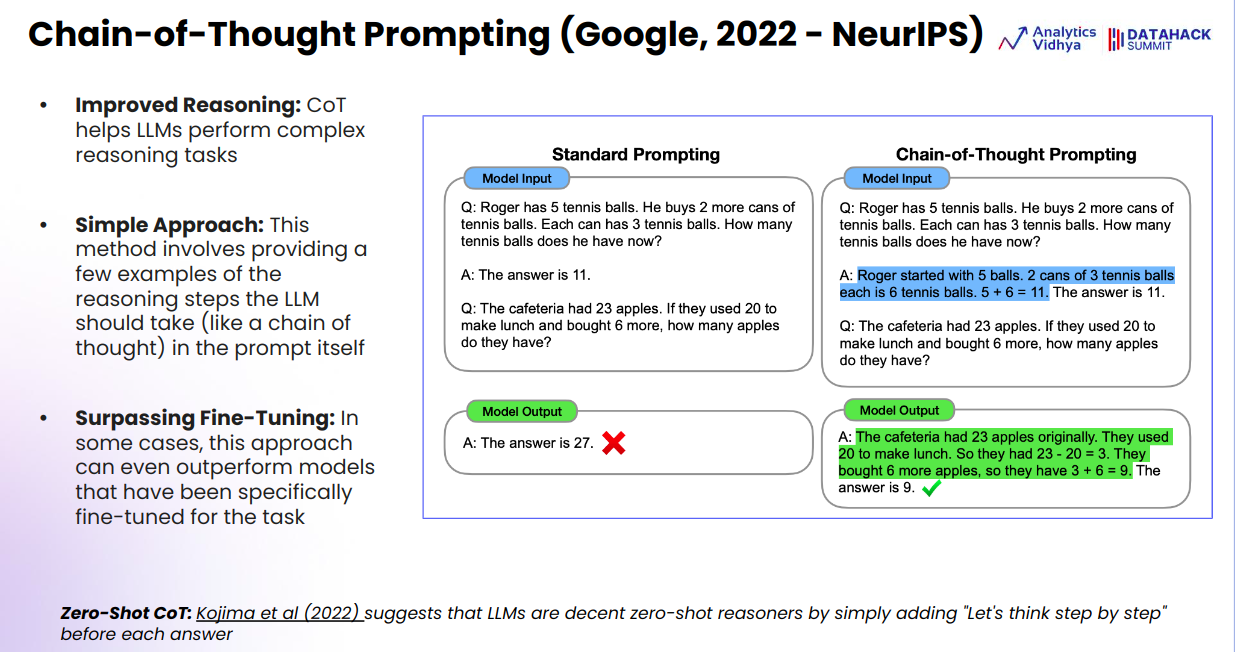
Chain of Thought (CoT) Prompting
- Method: CoT prompting entails breaking down the problem-solving course of into smaller, logical steps, guiding the mannequin to suppose by way of the issue step-by-step.
- Implementation: Within the CoT methodology, the mannequin is prompted with a thought course of as an alternative of simply asking for the ultimate reply. For instance, it’d break down the tennis ball drawback by first calculating the full variety of balls Roger buys after which including that to the present quantity.
- Advantages:
- Steerage: By explicitly instructing the mannequin to suppose step-by-step, it follows a logical sequence that results in the right reply.
- Effectiveness: CoT prompting can typically outperform even fine-tuned fashions, because it leverages the mannequin’s inherent reasoning capabilities with out requiring extra coaching.
- Zero-Shot Reasoning: Analysis talked about within the transcript (by a Japanese scientist Kojima) means that LLMs are able to first rate zero-shot reasoning when guided by way of a step-by-step course of. This implies they will resolve new issues they haven’t been explicitly educated on if given the best prompts.
Comparability Abstract
- Commonplace Prompting is easy however usually insufficient for advanced reasoning duties, because it lacks the mandatory steering for the mannequin.
- CoT Prompting enhances the mannequin’s reasoning capacity by offering a structured strategy to problem-solving, main to raised efficiency in duties requiring logical reasoning.
How can LLMs Act as Optimizers?

In a 2024 paper launched by Google, researchers evaluated varied prompting methods on the Nice Faculty Math knowledge benchmark. The baseline methodology used was the “let’s suppose step-by-step” strategy from Kojima et al. (2022), which achieved the very best accuracy with none examples (zero-shot). This methodology entails prompting the mannequin to “take a deep breath and work on the issue step-by-step.”
Different methods, reminiscent of “break this down” with PaLM 2L, yielded barely decrease outcomes. The paper focuses on optimizing prompts to deal with reasoning questions successfully. Researchers explored iterative strategies to find out the best immediate strings for answering questions, as understanding the mannequin’s interior workings may be difficult.
Right here’s the analysis paper:

Right here’s the Hyperlink: Massive Language Fashions as Optimizers
Different Immediate Engineering Strategies
Past Chain of Thought prompting, a number of different methods have proven promise in enhancing LLM reasoning capabilities:
Least to Most Successive Prompting
This method entails decomposing advanced issues into sub-questions, fixing them sequentially, and utilizing the solutions to construct as much as the ultimate answer. It’s significantly helpful for issues which are too advanced for normal CoT prompting.
A way launched at ICLR addresses limitations in Chain of Thought (CoT) prompting for advanced issues. This method, referred to as “Least to Most,” entails a two-step course of for dealing with extra intricate questions.
- Decomposition: In step one, the big language mannequin (LLM) breaks down the primary query into smaller sub-questions. The LLM doesn’t resolve these questions at this stage however merely identifies and lists them.
- Sequential Fixing: Within the second step, the LLM solves these sub-questions one after the other, utilizing the solutions from earlier sub-questions to tell the following ones.

As an example, suppose the primary query is about calculating the variety of instances Amy can slide down a slide inside a given timeframe. In that case, the LLM first determines the time taken for every slide (sub-question) after which makes use of this info to unravel the primary drawback.
The method is famous for its simplicity and effectiveness, and whereas it’s usually profitable, there are situations the place the LLM’s accuracy isn’t excellent. The method may be applied by producing sub-questions, fixing them iteratively, and utilizing codecs to information the LLM by way of problem-solving.
General, the “Least to Most” method improves problem-solving accuracy in advanced eventualities, reaching an accuracy of 91.4% in comparison with 94% with Chain of Thought prompting.
To see how this really works in apply, undergo the given code – Least-to-Most Prompting
Successive Prompting

Right here’s the Hyperlink: Successive Prompting for Decomposing Complicated Questions
Right here, we’re discussing the method referred to as “successive prompting,” developed by a researcher – Dheera Dua, presently at Google DeepMind however initially conceived earlier than their tenure on the firm. This method was offered on the EMNLP convention and contrasted with the “least to most” prompting methodology.
In “least to most” prompting, all sub-questions of a fancy drawback are recognized and answered sequentially. In distinction, “successive prompting” decouples the question-answering course of. As a substitute of figuring out all sub-questions without delay, it identifies and solutions one sub-question at a time, iterating till the ultimate reply is reached. This methodology is split into two phases: query decomposition and query answering.
Decomposition Stage
Within the query decomposition stage, the duty is to determine the following sub-question. This step isn’t about discovering the reply however figuring out which sub-question needs to be tackled subsequent. As soon as recognized, the question-answering stage entails fixing that sub-question. This iterative course of continues till all sub-questions are answered, resulting in the ultimate answer.
Additionally, the sensible implementation problem is that the size of prompts could make it troublesome to take care of give attention to an important elements of the issue. The answer proposed entails a standardized format to assist the mannequin determine construction and relevance. Nevertheless, this method might face limitations in advanced real-life functions, particularly the place hallucinations (incorrect or irrelevant outputs from the mannequin) are a priority.
The method was examined with a selected instance, figuring out sub-questions and trying to reply them. Whereas the strategy confirmed some potential, it solely achieved 82% accuracy, suggesting that it could not all the time outperform easier strategies like “least to most.” The dialogue additionally touches on potential enhancements, reminiscent of incorporating retrieval-augmented era (RAG) to boost the relevance of the examples utilized in every iteration.
Whereas successive prompting supplies a versatile, iterative strategy to problem-solving, its effectiveness varies with context and the issue’s nature.
Step-back Prompting
Right here’s the hyperlink: Take a Step Again: Evoking Reasoning by way of Abstraction in Massive Language Fashions
Step-back prompting encourages the LLM to think about high-level ideas or ideas earlier than trying to unravel the precise drawback. This strategy may be particularly efficient for domain-specific reasoning duties. It’s a methodology for bettering the accuracy and effectiveness of huge language fashions (LLMs). This strategy contrasts with different strategies like Chain of Thought (CoT) and immediate decomposition.
Step-back prompting first identifies key ideas or ideas earlier than fixing the primary query. For instance, as an alternative of instantly answering a query about an excellent gasoline’s stress, the LLM identifies related physics ideas, then makes use of this understanding to deal with the primary query.
Additionally, the step-back prompting is especially helpful in strategic evaluation eventualities, reminiscent of creating a go-to-market (GTM) technique. As a substitute of decomposing the issue into smaller elements, one ought to first decide a normal strategic precept (the “step again query”) earlier than answering the precise query.
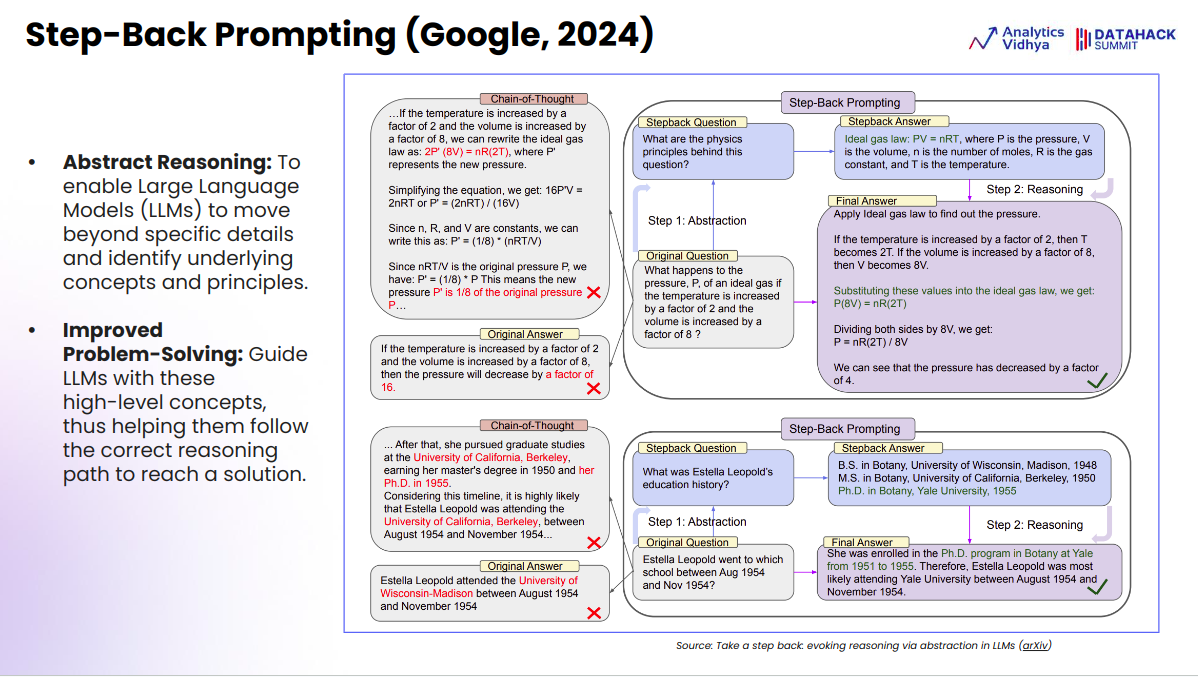
Furthermore, It emphasizes that combining step-back prompting with retrieval-augmented era (RAG) usually yields higher outcomes than fine-tuning fashions from scratch. In addition they define a structured immediate with examples, a predominant query, and a step-back query to information the LLM in producing correct responses. Lastly, a comparability of various prompting methods exhibits that step-back prompting, whereas efficient, performs barely decrease than the “least to most” methodology by way of accuracy.
In a nutshell, when iterating over the step-back prompting method, it achieves an accuracy of 81% on the precise dataset getting used. Compared, customary prompting yields an accuracy of 74%, whereas the Chain of Thought methodology reaches 90%. The “least to most” strategy performs greatest, with barely decrease outcomes for the successive prompting and step-back methods.
Interleaved Retrieval with CoT Prompting
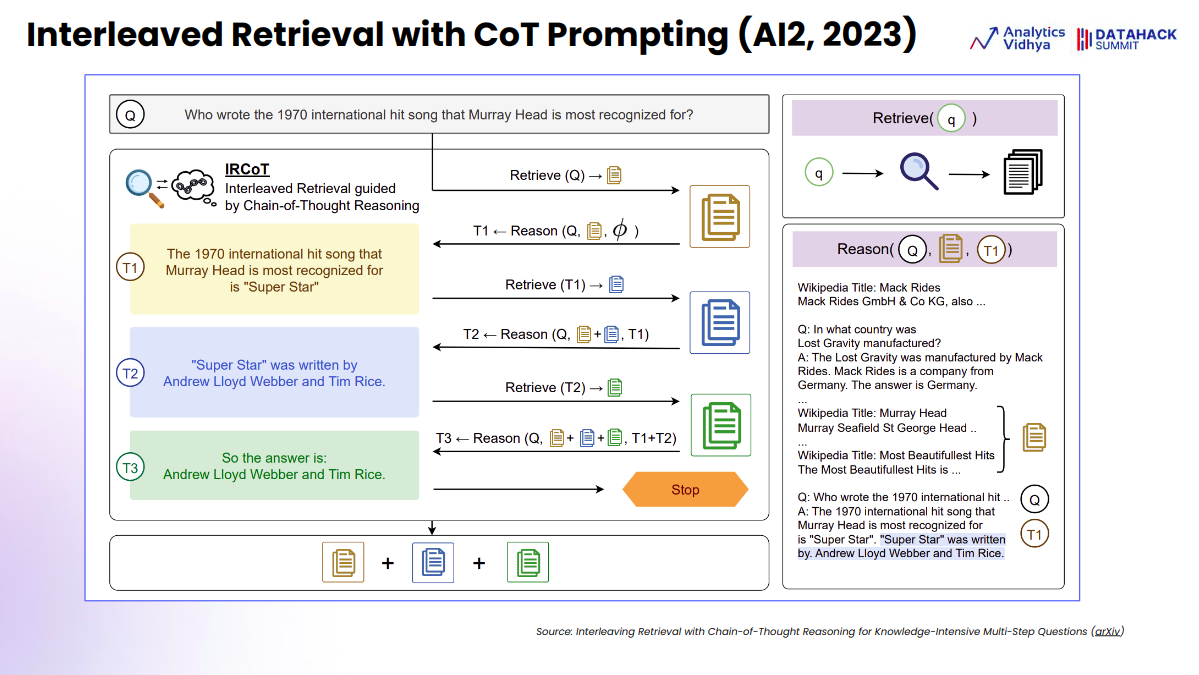
Right here, we’ll focus on a course of referred to as “interleaved retrieval with Chain of Thought (CoT) prompting,” which mixes info retrieval with reasoning to reply advanced questions. This methodology operates as follows:
- Preliminary Question and Retrieval: A query is posed, and step one entails retrieving a related doc chunk to enhance the immediate.
- Reasoning and Output Technology (T1): Based mostly on the retrieved doc and the query, the LLM (Massive Language Mannequin) generates an output (T1).
- Subsequent Retrieval and Reasoning: The LLM then routinely retrieves one other doc wanted to reply the query, reasoning once more with this new info and the earlier output to generate the following response (T2).
- Additional Iterations (T3): This strategy of retrieval and reasoning continues till sufficient related paperwork are gathered (T3) to reply the primary query comprehensively.
- Remaining Response: The outputs from all steps (T1, T2, T3) are mixed to kind the ultimate response.
The present implementation lacks steps reminiscent of figuring out the precise sub-questions and guaranteeing that the LLM’s responses absolutely reply the primary query. These steps have to be refined additional to enhance the method.

Right here’s the hyperlink: Interleaving Retrieval with Chain-of-Thought Reasoning for Information-Intensive Multi-Step Questions
Ensemble Strategies with Majority Voting
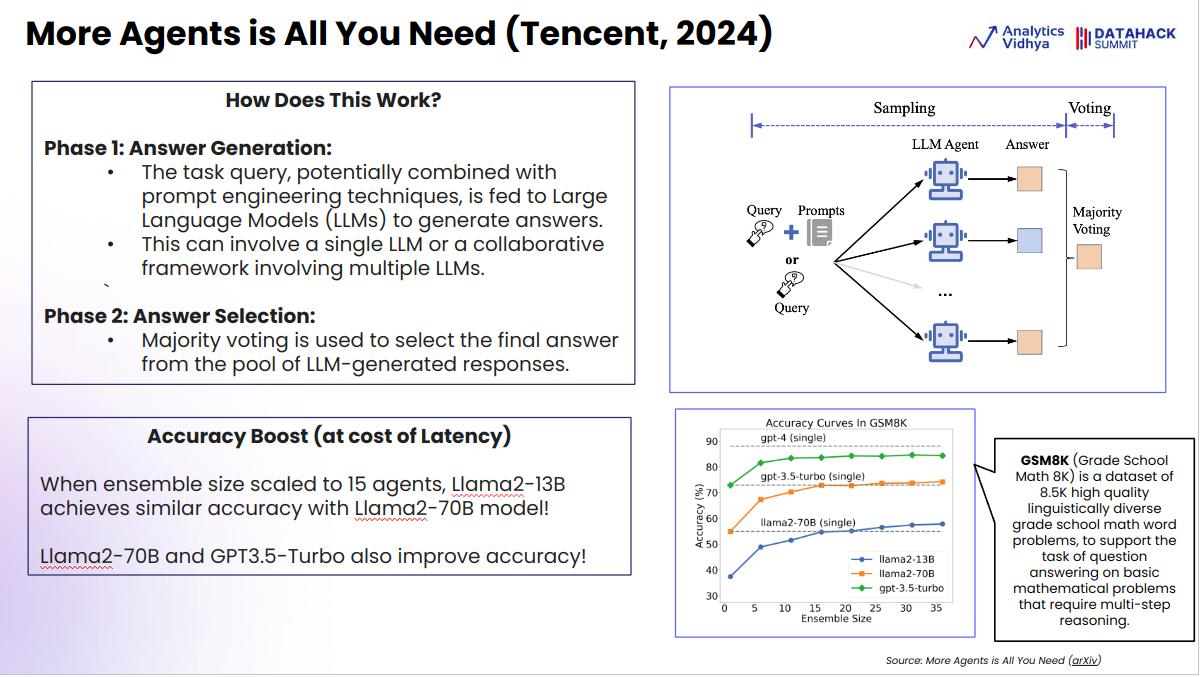
This methodology entails utilizing a number of LLM brokers or prompting methods to generate a number of solutions after which deciding on the commonest reply. This strategy will help cut back hallucinations and enhance total accuracy.
Right here, we focus on a analysis strategy proposed by Tencent, emphasizing the idea of utilizing a number of LLM (Massive Language Mannequin) brokers to unravel advanced reasoning issues. Earlier methods, reminiscent of LLM debates and Chain of Thought (CoT) self-consistency, encourage the concept, producing a number of reasoning chains or debates amongst LLM brokers to succeed in probably the most correct reply.

Right here’s the hyperlink: Extra Brokers Is All You Want
On this methodology, a number of LLM brokers are used to reply a question, after which a majority voting system is employed to find out the very best reply. The rationale is that even when some responses include hallucinations, the bulk will present constant and dependable solutions, lowering the affect of incorrect outputs.
The potential for utilizing totally different LLMs within the ensemble might result in extra diverse and strong outcomes, just like the range seen in random forests. The effectiveness of this strategy was examined utilizing LLaMA 2, the place an ensemble measurement of 15 to twenty brokers matched the efficiency of GPT-3.5 on a benchmark take a look at. Nevertheless, the strategy requires vital computational sources, because it entails operating a number of LLM situations and aggregating their outputs.
Hypothetical Doc Embeddings (HyDE)
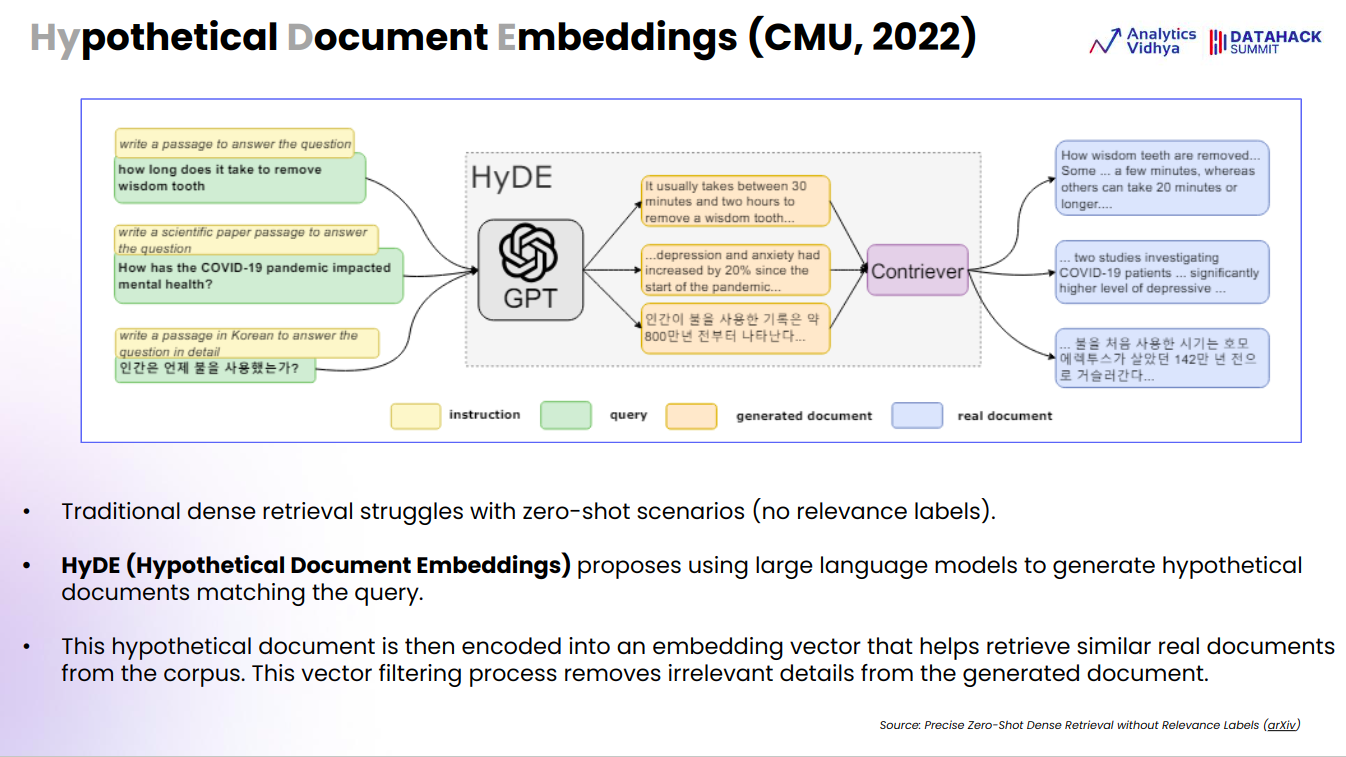
The HyDE (Hypothetical Doc Embeddings) methodology provides a sensible answer to the constraints of conventional dense retrieval methods, significantly in zero-shot eventualities the place no related labels can be found. By producing hypothetical paperwork by way of massive language fashions, HyDE can create contextually related content material that aligns with a question, even when prior examples or coaching knowledge are missing. This makes it well-suited for duties that require retrieving info in unfamiliar or novel contexts.
A key power of this strategy is its capacity to filter out irrelevant info from the generated hypothetical doc when changing it into embedding vectors. This ensures that the retrieval system focuses on the core points of the question, thereby bettering accuracy. In contrast to conventional methods which may battle with ambiguous or advanced queries, HyDE can simulate a spread of doable paperwork and match them to actual content material, which makes it extra strong.
For my part, HyDE represents an modern development in retrieval methods by combining generative capabilities with vector-based retrieval. It leverages the creativity and adaptability of huge language fashions to create extra nuanced, contextually wealthy embeddings. This hybrid strategy can considerably enhance the retrieval of related paperwork, particularly in fields like authorized, tutorial, or technical domains, the place typical strategies would possibly fall quick because of an absence of coaching knowledge or relevance labels.
Reasoning With out Remark (ReWOO)
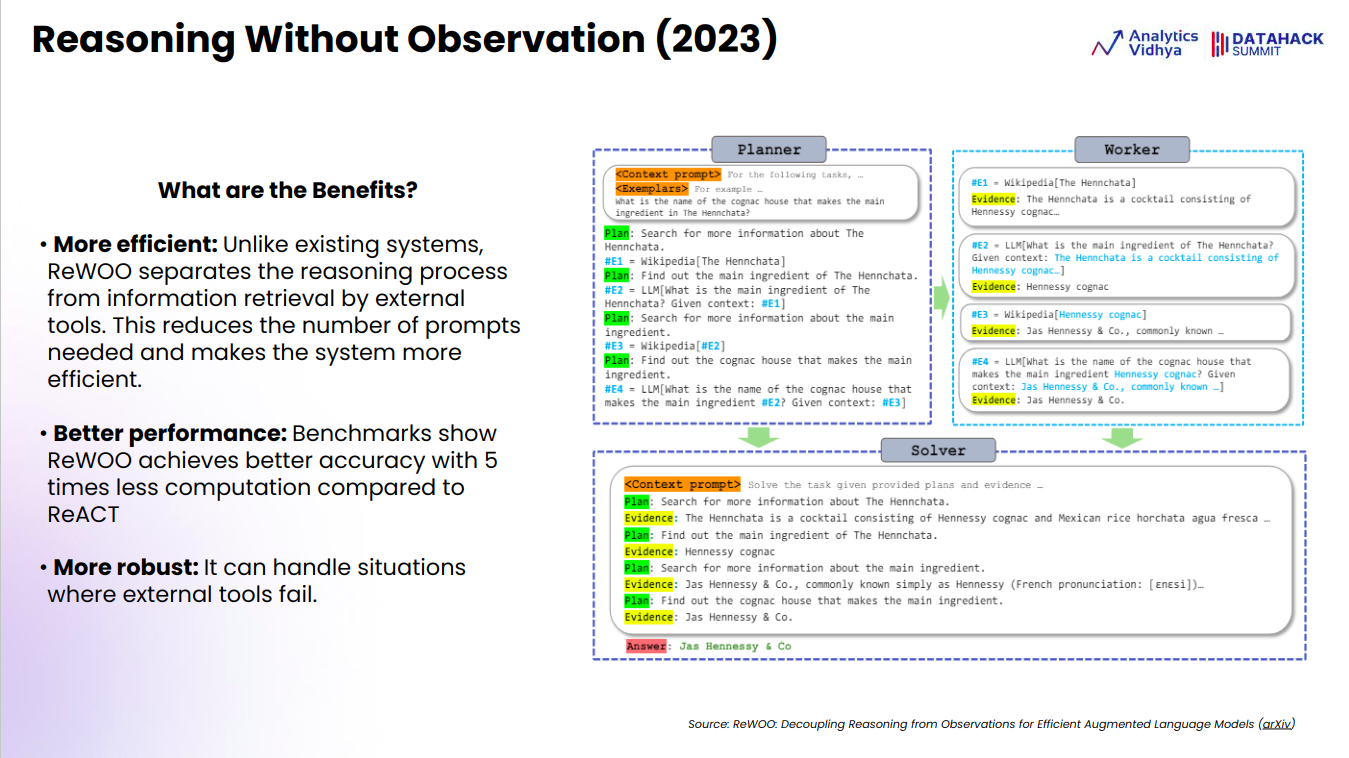
ReWOO, launched in 2023, marks a major development in AI reasoning methods. In contrast to conventional approaches that intertwine reasoning with info retrieval, ReWOO effectively separates these processes. This results in fewer prompts, making the system extra environment friendly and faster.
ReWOO additionally demonstrates superior efficiency, reaching increased accuracy whereas requiring 5 instances much less computational energy than earlier fashions like ReACT. One other key benefit of ReWOO is its robustness; it successfully handles conditions the place exterior instruments would possibly fail, guaranteeing extra dependable outcomes throughout varied eventualities.
In abstract, ReWOO stands out for its effectivity, enhanced efficiency, and resilience, providing a strong answer for AI-driven reasoning duties.
Working Sensible Experiments Utilizing Superior Prompting Strategies
We’ll discover an implementation utilizing the Discrete Reasoning over Paragraphs dataset to display the effectiveness of immediate engineering methods.
Description of the Dataset
The dataset contains 96,000 questions requiring multi-step reasoning primarily based on given paragraphs. This instance makes use of a subset of 240 annotated examples, 140 of that are for analysis and 100 of that are for few-shot examples.
Implementation Particulars (Utilizing LangChain)
The implementation makes use of the LangChain library and a Hugging Face API token. Key steps embrace:
- Establishing the setting and loading the mannequin
- Creating immediate templates for various prompting methods
- Implementing analysis features
We began by organising the setting and transferring on to utilizing LangChain. Right here, Mannequin ID “Mixtral” with an open-source mannequin is used to create a tokenizer from the pre-trained mannequin. Utilizing the Hugging Face API, we name the language mannequin and format the immediate. We make a immediate template the place an enter variable is used, and this format is utilized by default when prompting the language mannequin. We use LangChain’s expression language to question and display the mannequin with an instance query about ECG (electrocardiography). Moreover, we created a perform to load the embedding mannequin.
Analysis Metrics: Comparability of Prompting Strategies for Massive Language Fashions
The first metric used is accuracy, evaluating the LLM’s solutions to the bottom reality solutions within the dataset.
Within the analysis process, we restructured knowledge from JSON right into a extra structured format, specializing in a dataset of 240 examples categorized into 14 varieties of questions. We extracted 140 examples for our analysis. We employed a big language mannequin (LLM) to find out the correctness of solutions by prompting it to judge whether or not the LLM-generated responses have been right or incorrect.
In customary prompting, we ask the LLM to answer consumer queries with concise info, offering a one-shot instance and evaluating its accuracy. Utilizing this strategy, we noticed an accuracy price of 74% from 140 examples.
We modified the strategy for Chain of Thought (CoT) prompting by together with a further column in our knowledge body for CoT reasoning. This method concerned a two-step course of: first figuring out related knowledge after which performing the mandatory reasoning to reply the query. Implementing CoT considerably improved accuracy to 90%.
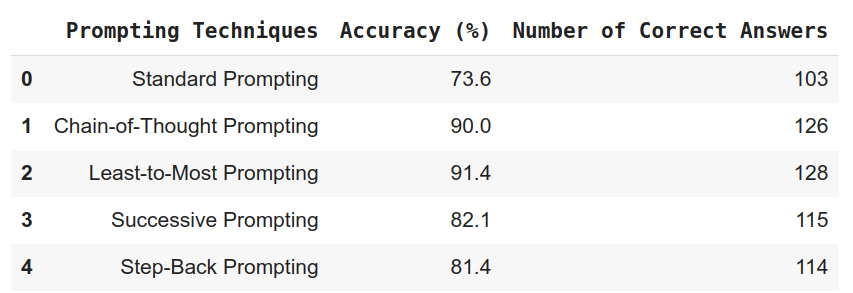
After going by way of all of the methods, we showcase the effectiveness of varied prompting methods by evaluating their accuracy and the variety of right solutions. Commonplace prompting, which asks a query instantly, has the bottom accuracy at 73.6%, with 103 right solutions. Chain-of-Thought (CoT) prompting, which guides the mannequin step-by-step, improves accuracy to 90.0%, with 126 right solutions. Least-to-most prompting, the place easier elements are solved first, achieves the very best accuracy at 91.4%, with 128 right solutions. Successive prompting, refining solutions by way of a number of prompts, reaches 82.1% accuracy with 115 right solutions. Step-back prompting, asking the mannequin to rethink, leads to 81.4% accuracy and 114 right solutions. Structured reasoning methods like Least-to-Most and CoT outperform customary prompting, highlighting the worth of guided reasoning.
For higher understanding, right here is the Colab pocket book.
Conclusion
Immediate engineering methods have proven vital potential in enhancing the logical reasoning capabilities of LLMs. Within the instance implementation, Chain of Thought prompting improved accuracy from 74% to 90%, whereas Least to Most Successive Prompting achieved the very best accuracy at 91.4%.
Future Analysis Instructions
- Interleaved Retrieval with CoT Prompting: Combining info retrieval with reasoning processes for extra advanced, real-world functions.
- Multi-agent Approaches: Exploring using a number of LLM brokers for debate-style reasoning and ensemble strategies.
- Optimizing Immediate Technology: Growing methods to generate the best prompts for particular reasoning duties routinely.
- Addressing Hallucinations: Additional analysis is required to scale back hallucinations and enhance the reliability of LLM reasoning outputs.
As LLMs proceed to evolve, immediate engineering stays an important space of analysis and growth. By refining these methods, we are able to unlock LLMs’ full potential for advanced reasoning duties throughout varied domains, bringing us nearer to extra strong and dependable AI methods.
If you’re on the lookout for generative AI programs on-line then discover – GenAI Pinnacle Program
Steadily Requested Questions
Ans. Immediate engineering entails designing efficient enter prompts to information LLMs’ reasoning course of. It might considerably improve an LLM’s capacity to carry out advanced duties by offering structured steering, resulting in extra correct and logical outputs.
Ans. A number of methods embrace Chain of Thought (CoT) prompting, Least to Most Successive Prompting, Step-back Prompting, Successive Prompting, and Interleaved Retrieval with CoT Prompting.
Ans. CoT prompting considerably improves accuracy. Within the instance given, customary prompting achieved 74% accuracy, whereas CoT prompting improved this to 90% accuracy.
Ans. This method entails breaking down advanced issues into smaller sub-questions, fixing them sequentially, and utilizing the solutions to construct as much as the ultimate answer. It achieved the very best accuracy (91.4%) within the research talked about.
Ans. The sensible utility makes use of the Discrete Reasoning over Paragraphs dataset. It exhibits how totally different methods may be applied utilizing libraries like LangChain and evaluates their effectiveness in bettering LLM efficiency on advanced reasoning duties.
Hello, I’m Pankaj Singh Negi – Senior Content material Editor | Keen about storytelling and crafting compelling narratives that rework concepts into impactful content material. I really like studying about expertise revolutionizing our way of life.