All of the code is offered in this GitHub repository.
Introduction
Synchronizing information from exterior relational databases like Oracle, MySQL, or an information warehouse into the Databricks Information Intelligence Platform is a typical use case. Databricks provides a number of approaches starting from LakeFlow Join’s easy and environment friendly ingestion connectors to Delta Dwell Tables’ (DLT) flexibility with APPLY CHANGES INTO assertion, which accepts change information seize (CDC) enter datasets. Beforehand, in “Simplifying Change Information Seize with Databricks Delta Dwell Tables“, we described how DLT pipelines allow you to develop scalable, dependable, and low-latency information pipelines to carry out CDC processing in your information lake with the minimal required computation assets and computerized out-of-order information dealing with.
Nevertheless, whereas LakeFlow Join and DLT APPLY CHANGES INTO work seamlessly with databases that may present a change information feed (CDF) to stream modifications from, there are environments and techniques the place a CDF stream shouldn’t be accessible. For these sources, you possibly can examine snapshots to determine modifications and course of them. On this weblog, we are going to present you learn how to implement SCD Kind 1 and SCD Kind 2 in Databricks Delta Dwell Tables utilizing desk snapshots.
Understanding Slowly Altering Dimensions
Slowly altering dimensions (SCD) refers back to the unpredictable and sporadic change of knowledge throughout sure dimensions over time. These modifications may end up from correcting an error within the information or can characterize a real replace and worth change in that individual dimension, similar to buyer location info or product element info. A traditional instance is when a buyer strikes and modifications their deal with.
When working with information, it’s vital to make sure that modifications are precisely mirrored with out compromising information consistency. The choice to overwrite outdated values with new ones or seize modifications whereas retaining historic data can considerably impression your information pipelines and enterprise processes. This choice relies upon closely in your particular enterprise necessities. To deal with totally different use instances, there are numerous kinds of Slowly Altering Dimensions (SCD). This weblog will deal with the 2 commonest ones: SCD Kind 1, the place the dimension is overwritten with new information, and SCD Kind 2, the place each new and outdated data are maintained over time.
What are snapshots and why do they matter?
Snapshots characterize a secure view of the info at a selected time limit and might be explicitly or implicitly timestamped at a desk or file stage. These timestamps permit the upkeep of temporal information. A sequence of snapshots over time can present a complete view of the enterprise’s historical past.
With out monitoring the historical past of data, any analytical report constructed on outdated data shall be inaccurate and might be deceptive for the enterprise. Thus, monitoring the modifications in dimensions precisely is essential in any information warehouse. Whereas these modifications are unpredictable, evaluating snapshots makes it simple to trace modifications over time so we will make correct reviews based mostly on the freshest information.
Environment friendly Methods for RDBMS Desk Snapshots Administration: Push vs. Pull
Push-Primarily based Snapshots: Direct and Environment friendly
The Push-Primarily based method entails instantly copying your entire content material of a desk and storing this copy in one other location. This technique might be applied utilizing database vendor-specific desk replication or bulk operations. The important thing benefit right here is its directness and effectivity. You, because the consumer, provoke the method, leading to a right away and full replication of the info.
Pull-Primarily based Snapshots: Versatile however Useful resource-Intensive
Then again, the Pull-Primarily based method requires you to question the supply desk to retrieve its complete content material. That is sometimes accomplished over a JDBC connection from Databricks, and the retrieved information is then saved as a snapshot. Whereas this technique provides extra flexibility when it comes to when and the way information is pulled, it may be costly and won’t scale nicely with very massive desk sizes.
In the case of dealing with a number of variations of those snapshots, there are two primary methods:
Snapshot Alternative Strategy (Strategy 1): This technique is about sustaining solely the most recent model of a snapshot. When a brand new snapshot turns into accessible, it replaces the outdated one. This method is good for situations the place solely essentially the most present information snapshot is related, lowering storage prices and simplifying information administration.
Snapshot Accumulation Strategy (Strategy 2): Opposite to the Alternative Strategy, right here you retain a number of variations of desk snapshots. Every snapshot is saved at a novel path, permitting for historic information evaluation and monitoring modifications over time. Whereas this technique gives a richer historic context, it calls for extra storage and a extra advanced system administration.
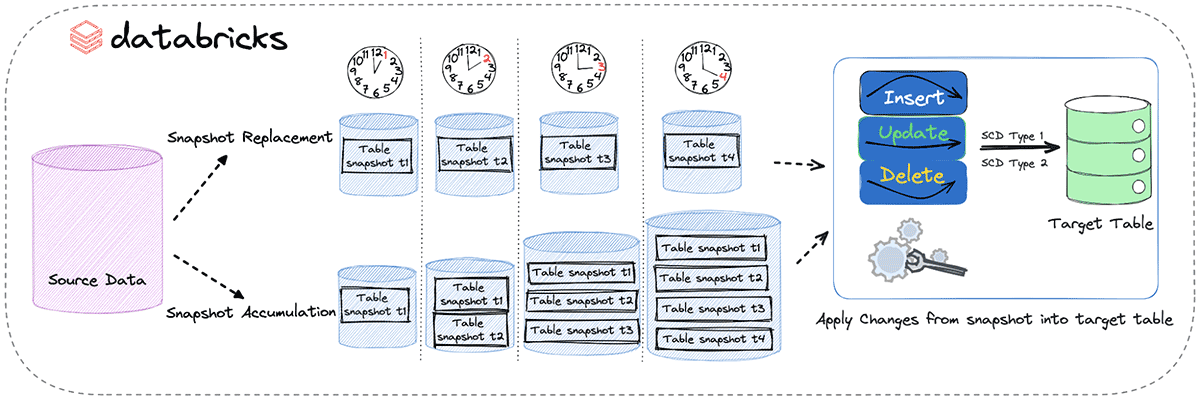
Introduction to Delta Dwell Tables Apply Modifications From Snapshot
DLT has a functionality known as “APPLY CHANGES FROM SNAPSHOT“, which permits information to be learn incrementally from a sequence of full snapshots. Full snapshot contains all data and their corresponding states, providing a complete view of the info because it exists at that second. Utilizing APPLY CHANGES FROM SNAPSHOT assertion now you can seamlessly synchronize exterior RDBMS sources into the Databricks platform utilizing full snapshots of the supply databases.
APPLY CHANGES FROM SNAPSHOT provides a easy, declarative syntax to effectively decide the modifications made to the supply information by evaluating a sequence of in-order snapshots whereas permitting customers to simply declare their CDC logic and observe historical past as SCD sorts 1 or 2.
Earlier than we dive deeper and undergo an instance utilizing this new characteristic, let’s take a look at the necessities and notes a consumer ought to overview earlier than leveraging this new functionality in DLT:
- This characteristic solely helps Python.
- The characteristic is supported on serverless DLT pipelines, and on the non-serverless DLT pipeline with Professional and Superior product editions,
- Snapshots handed into the assertion should be in ascending order by their model.
- The snapshot model parameter within the APPLY CHANGES FROM SNAPSHOT assertion should be a sortable information kind (e.g. string and quantity sorts).
- Each SCD Kind 1 and SCD Kind 2 strategies are supported.
Following this weblog you possibly can leverage the APPLY CHANGES FROM SNAPSHOT assertion and implement both the snapshot substitute or accumulation method in each the Hive Metastore and Unity Catalog environments.
Outline your supply desk
Let’s discover this idea utilizing on-line purchasing for instance. Whenever you store on-line, merchandise costs can fluctuate resulting from provide and demand modifications. Your order goes via levels earlier than supply, and also you would possibly return and reorder objects at decrease costs. Retailers profit from monitoring this information. It helps them handle stock, meet buyer expectations, and align with gross sales objectives.
To showcase the net purchasing instance utilizing the primary method (snapshot substitute method), we are going to use the complete snapshot information saved within the storage location, and as quickly as a brand new full snapshot turns into accessible, we are going to exchange the present snapshot with the brand new one. For the second method (snapshot accumulation method), we are going to depend on the hourly full information snapshots. As every new snapshot turns into accessible, we write the newly arrived information to the storage location storing all the present snapshots. Snapshots of knowledge load frequency might be set to no matter frequency is required for processing snapshots. You would possibly have to course of the snapshots roughly regularly. Right here for simplicity, we choose the hourly full snapshots, that means that each hour a full copy of the data with their newest updates for that corresponding hour is loaded and saved in our storage location. Beneath is an instance of how our hourly full snapshots are saved within the managed Unity Catalog Volumes.
The under desk represents the data saved for instance of a full snapshot:
| order_id | value | order_status | order_date | customer_id | product_id |
|---|---|---|---|---|---|
| 1 | 91 | re-ordered | 2023-09-16 13:59:15 | 17127 | 2058 |
| 2 | 24 | transport | 2023-09-13 15:52:53 | 16334 | 2047 |
| 3 | 13 | delivered | 2023-10-04 01:07:35 | 10706 | 2005 |
| … | … | … | … | … | … |
When creating snapshot information, you will need to have a main key for every file in your information and a single timestamp or model quantity that applies to all data in every snapshot that permits easy monitoring of the order of modifications in a sequence of ingested snapshots. On this day by day snapshot instance, order_id serves as the first key. The date related to loading of the snapshots into the storage location is used to call the information, enabling us to entry the snapshot for that particular date, and we depend on these date-based file names to trace modifications between consecutive snapshots.
For this instance, we have created a pattern dataset utilizing the fields from the desk talked about earlier. To reveal an replace operation, we modify the order_status from ‘pending’ to ‘transport’, ‘delivered’, or ‘cancelled’ for present orders. For instance inserts, we add new orders with distinctive order_ids. Lastly, to point out how deletes work, we take away a small, random collection of present orders. This method gives a complete instance that features all key operations: INSERT, UPDATE, and DELETE. You could find all of the notebooks used for this weblog, together with the info generator, right here. The processing steps and outcomes are demonstrated within the following sections.
Implementation of a DLT pipeline to course of CDC information from Full Snapshots
As a way to leverage “APPLY CHANGES FROM SNAPSHOT”, much like APPLY CHANGES INTO, we should first create the goal streaming desk that shall be used to seize and retailer the file modifications over time. The under code is an instance of making a goal streaming desk.
import dlt
dlt.create_streaming_table(title="goal",
remark="Clear, merged last desk from the complete snapshots")Now that now we have a goal streaming desk, we will look at the APPLY CHANGES FROM SNAPSHOT assertion extra carefully and look at the arguments it must course of the snapshot information successfully. In Strategy 1, when each present snapshot is periodically changed by a brand new snapshot, the apply_changes_from_snapshot Python perform reads and ingests a brand new snapshot from a supply desk and shops it in a goal desk.
@dlt.view(title="supply")
def supply():
return spark.learn.desk("catalog.schema.desk")
def apply_changes_from_snapshot(
goal="goal",
supply="supply",
keys=["keys"],
stored_as_scd_type,
track_history_column_list = None,
track_history_except_column_list = None)APPLY CHANGES FROM SNAPSHOT requires specifying the “keys” argument. The “keys” argument ought to seek advice from the column or mixture of columns that uniquely determine a row within the snapshot information. This can be a distinctive identifier that permits the assertion to determine the row that has modified within the new snapshots. For instance in our on-line purchasing instance, “order_id” is the first key and is the distinctive identifier of orders that acquired up to date, deleted, or inserted. Thus, later within the assertion we move order_id to the keys argument.
One other required argument is stored_as_scd_type. The stored_as_scd_type argument permits the customers to specify how they want to retailer data within the goal desk, whether or not as SCD TYPE 1 or SCD Kind 2.
In Strategy 2, the place snapshots accumulate over time and we have already got a listing of present snapshots, as a substitute of utilizing the supply argument, we’d like one other argument known as snapshot_and_version that should be specified. The snapshot model should be explicitly supplied for every snapshot. This snapshot_and_version argument takes a lambda perform. By passing a lambda perform to this argument, the perform takes the most recent processed snapshot model as an argument.
Lambda perform: lambda Any => Non-obligatory[(DataFrame, Any)]
Return: it may both be None or a tuple of two values:
- The primary worth of the returned tuple is the brand new snapshot DataFrame to be processed.
- The second worth of the returned tuple is the snapshot model that represents the logical order of the snapshot.
Every time the apply_changes_from_snapshot pipeline will get triggered, we are going to:
- Execute the snapshot_and_version lambda perform to load the subsequent snapshot DataFrame and the corresponding snapshot model.
- If there aren’t any DataFrame returns, we are going to terminate the execution and mark the replace as full.
- Detect the modifications launched by the brand new snapshot and incrementally apply them to the goal.
- Soar again to step one (#1) to load the subsequent snapshot and its model.
Whereas the above-mentioned arguments are the necessary fields of APPLY CHANGES FROM SNAPSHOT, different optionally available arguments, similar to track_history_column_list and track_history_except_column_list, give customers extra flexibility to customise the illustration of the goal desk if they should.
Going again to the net purchasing instance and taking a more in-depth have a look at how this characteristic works utilizing the synthetically generated information from [table 1]: Beginning with the primary run, when no preliminary snapshots existed, we generate order information to create the primary snapshot desk in case of Strategy 1, or retailer the generated preliminary snapshot information into the outlined storage location path utilizing managed Unity Catalog quantity in case of Strategy 2. Whatever the method, the generated information would appear like under:
| order_id | value | order_status | order_date | customer_id | product_id |
|---|---|---|---|---|---|
| 1 | 91 | re-ordered | 2023-09-16 13:59:15 | 17127 | 2058 |
| 2 | 24 | returned | 2023-09-13 15:52:53 | 16334 | 2047 |
| 3 | 13 | delivered | 2023-10-04 01:07:35 | 10706 | 2005 |
| 4 | 45 | cancelled | 2023-10-06 10:40:38 | 10245 | 2089 |
| 5 | 41 | transport | 2023-10-08 14:52:16 | 19435 | 2057 |
| 6 | 38 | delivered | 2023-10-04 14:33:17 | 19798 | 2061 |
| 7 | 27 | pending | 2023-09-15 03:22:52 | 10488 | 2033 |
| 8 | 23 | returned | 2023-09-14 14:50:19 | 10302 | 2051 |
| 9 | 96 | pending | 2023-09-28 22:50:24 | 18909 | 2039 |
| 10 | 79 | cancelled | 2023-09-29 15:06:21 | 14775 | 2017 |
The subsequent time the job triggers, we get the second snapshot of orders information wherein new orders with order ids of 11 and 12 have been added, and among the present orders in preliminary snapshots (order ids of seven and 9) are getting up to date with the brand new order_status, and the order id 2 which was an outdated returned order is now not exists. So the second snapshot would appear like under:
| order_id | value | order_status | order_date | customer_id | product_id |
|---|---|---|---|---|---|
| 1 | 91 | re-ordered | 2023-09-16 13:59:15 | 17127 | 2058 |
| 3 | 13 | delivered | 2023-10-04 01:07:35 | 10706 | 2005 |
| 4 | 45 | cancelled | 2023-10-06 10:40:38 | 10245 | 2089 |
| 5 | 41 | transport | 2023-10-08 14:52:16 | 19435 | 2057 |
| 6 | 38 | delivered | 2023-10-04 14:33:17 | 19798 | 2061 |
| 7 | 27 | delivered | 2023-10-10 23:08:24 | 10488 | 2033 |
| 8 | 23 | returned | 2023-09-14 14:50:19 | 10302 | 2051 |
| 9 | 96 | transport | 2023-10-10 23:08:24 | 18909 | 2039 |
| 10 | 79 | cancelled | 2023-09-29 15:06:21 | 14775 | 2017 |
| 11 | 91 | returned | 2023-10-10 23:24:01 | 18175 | 2089 |
| 12 | 24 | returned | 2023-10-10 23:39:13 | 13573 | 2068 |
Within the case of Strategy 1, the snapshot desk of “orders_snapshot” is now being overwritten by the latest snapshot information. To course of the snapshot information we first create a goal streaming desk of “orders”.
import dlt
from datetime import datetime
import datetime
database_name = spark.conf.get("snapshot_source_database")
desk = "orders_snapshot"
table_name = f"{database_name}.{desk}"
snapshot_source_table_name = f"{database_name}.orders_snapshot"
@dlt.view(title="supply")
def supply():
return spark.learn.desk(snapshot_source_table_name)
dlt.create_streaming_table(
title = "orders"
)Then we use the apply_changes_from_snapshot as under to use the most recent modifications on each order_id from the latest snapshot information into the goal desk. On this instance, as a result of we need to course of the brand new snapshot, we learn the brand new snapshot from the snapshot information supply and retailer the processed snapshot information within the goal desk.
dlt.apply_changes_from_snapshot(
goal = "orders",
supply = "supply",
keys = ["order_id"],
stored_as_scd_type = 1
)Much like Strategy 1, to course of the snapshots information for Strategy 2 we first have to create a goal streaming desk. We name this goal desk “orders”.
import dlt
from datetime import timedelta
from datetime import datetime
dlt.create_streaming_table(title="orders",
remark= "Clear, merged last desk from the complete snapshots",
table_properties={
"high quality": "gold"
}
)For Strategy 2, each time the job is triggered and new snapshot information is generated, the info is saved in the identical outlined storage path the place the preliminary snapshot information was saved. As a way to consider if this path exists and to seek out the preliminary snapshot information, we record the contents of the outlined path, then we convert the datetime strings extracted from the paths into datetime objects, and compile a listing of those datetime objects. After now we have the entire record of datetime objects, by discovering the earliest datetime on this record we determine the preliminary snapshot saved within the root path listing.
snapshot_root_path = spark.conf.get("snapshot_path")
def exist(path):
strive:
if dbutils.fs.ls(path) is None:
return False
else:
return True
besides:
return False
# Listing all objects within the bucket utilizing dbutils.fs
object_paths = dbutils.fs.ls(snapshot_root_path)
datetimes = []
for path in object_paths:
# Parse the datetime string to a datetime object
datetime_obj = datetime.strptime(path.title.strip('/"'), '%Y-%m-%d %H')
datetimes.append(datetime_obj)
# Discover the earliest datetime
earliest_datetime = min(datetimes)
# Convert the earliest datetime again to a string if wanted
earliest_datetime_str = earliest_datetime.strftime('"%Y-%m-%d %H"')
print(f"The earliest datetime within the bucket is: {earliest_datetime_str}")As talked about earlier in Strategy 2, each time the apply_changes_from_snapshot pipeline will get triggered, the lambda perform must determine the subsequent snapshot that must be loaded and the corresponding snapshot model or timestamp to detect the modifications from the earlier snapshot.
As a result of we’re utilizing hourly snapshots and the job triggers each hour, we will use increments of 1 hour together with the extracted datetime of the preliminary snapshot to seek out the subsequent snapshot path, and the datetime related to this path.
def next_snapshot_and_version(latest_snapshot_datetime):
latest_datetime_str = latest_snapshot_datetime or earliest_datetime_str
if latest_snapshot_datetime is None:
snapshot_path = f"{snapshot_root_path}/{earliest_datetime_str}"
print(f"Studying earliest snapshot from {snapshot_path}")
earliest_snapshot = spark.learn.format("parquet").load(snapshot_path)
return earliest_snapshot, earliest_datetime_str
else:
latest_datetime = datetime.strptime(latest_datetime_str, '%Y-%m-%d %H')
# Calculate the subsequent datetime
increment = timedelta(hours=1) # Increment by 1 hour as a result of we're
supplied hourly snapshots
next_datetime = latest_datetime + increment
print(f"The subsequent snapshot model is : {next_datetime}")
# Convert the next_datetime to a string with the specified format
next_snapshot_datetime_str = next_datetime.strftime('%Y-%m-%d %H')
snapshot_path = f"{snapshot_root_path}/{next_snapshot_datetime_str}"
print("Making an attempt to learn subsequent snapshot from " + snapshot_path)
if (exist(snapshot_path)):
snapshot = spark.learn.format("parquet").load(snapshot_path)
return snapshot, next_snapshot_datetime_str
else:
print(f"Could not discover snapshot information at {snapshot_path}")
return NoneAs soon as we outline this lambda perform and may determine modifications in information incrementally, we will use the apply_changes_from_snapshot assertion to course of the snapshots and incrementally apply them to the created goal desk of “orders”.
dlt.apply_changes_from_snapshot(
goal="orders",
snapshot_and_version=next_snapshot_and_version,
keys=["order_id"],
stored_as_scd_type=2,
track_history_column_list=["order_status"]
)Whatever the method, as soon as the code is prepared, to make use of the apply_changes_from_snapshot assertion, a DLT pipeline utilizing the Professional or Superior product version should be created.
Develop Workflows with Delta Dwell Tables Pipeline as Duties Utilizing Databricks Asset Bundles (DABs)
To simplify the event and deployment of our pattern workflow, we used Databricks Asset Bundles (DABs). Nevertheless, the APPLY CHANGES performance doesn’t mandate the usage of DABs, however it’s thought of a finest observe to automate the event and deployment of Databricks Workflows and DLT pipelines.
For each frequent approaches we’re protecting on this weblog we leveraged from DABs in this repo. Thus within the repo there are supply information known as databricks.yml which function an end-to-end mission definition. These supply information embrace all of the parameters and details about how DLT pipelines as duties inside workflows might be examined and deployed. On condition that DLT pipelines present you two storage choices of Hive Metastore and Unity Catalog, within the databricks.yml file we thought of each storage choices for implementations of each Strategy 1 and Strategy 2 jobs. The goal “improvement” in databricks.yml file refers back to the implementation of each approaches utilizing Hive Metastore and in DBFS location, whereas goal known as “development-uc” within the databricks.yml file refers back to the implementation of each approaches utilizing Unity Catalog and storing information in managed UC Volumes. Following the README.md file within the repo it is possible for you to to deploy each approaches in both storage choice of your selection solely through the use of just a few bundle instructions.
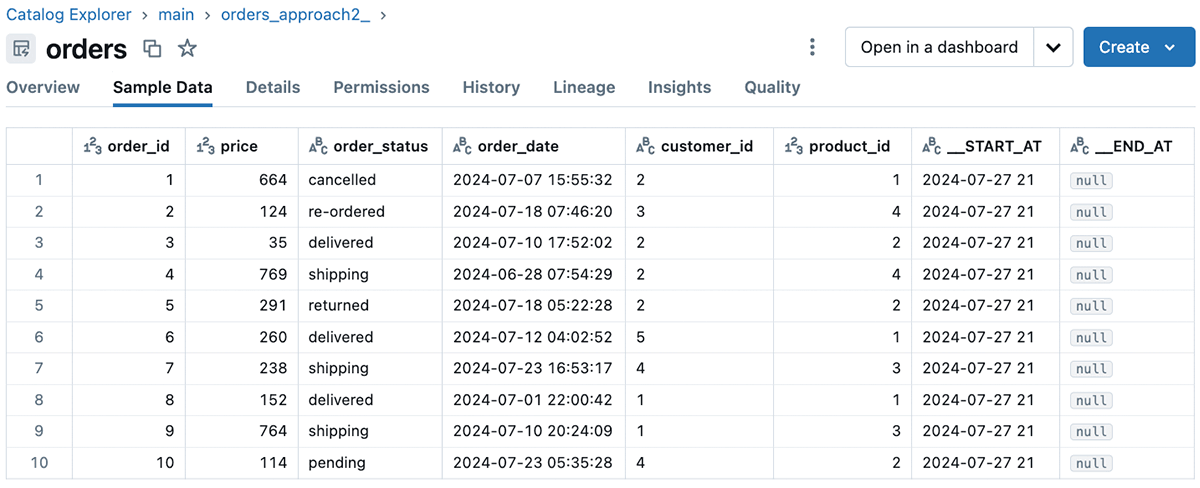
Within the instance we coated Strategy 2 we used SCD Kind 2 goal desk via passing 2 to the stored_as_scd_type argument to retailer all of the historic and present values of the order ids within the goal desk. Navigating to the goal desk via Catalog Explorer, we will see the columns of the goal desk, pattern information, particulars, and extra insightful fields related to the goal desk. For SCD Kind 2 modifications, Delta Dwell Tables propagates the suitable sequencing values to the __START_AT and __END_AT columns of the goal desk. See under for an instance of pattern information from the goal desk in Catalog Explorer when utilizing Unity Catalog. The catalog “primary” within the picture under is the default catalog within the Unity Catalog metastore, which we’re counting on on this instance for simplicity.
Getting Began
Constructing a scalable, dependable incremental information pipeline based mostly on snapshots has by no means been simpler. Strive Databricks without spending a dime to run this instance.